· Tutorial
Jak tworzyć transkrypcje podcastów z użyciem AI?

TL;DR
Tworzenie transkrypcji opiera się o narzędzia takie jak Make.com, AssemblyAI, OpenAI API oraz arkusze Google Sheets. Zobacz opis całego projektu.
Sprint automatyzacyjny
W dzisiejszym artykule opiszę jak zautomatyzować proces tworzenia transkrypcji podcastów z użyciem sztucznej inteligencji. W projekcie wykorzystamy narzędzia takie jak Make.com, AssemblyAI, OpenAI API oraz arkusze Google Sheets. Cała inicjatywa to część sprintu automatyzacji, który stał się naszym priorytetem na pierwszy miesiąc wakacji.
Transkrypcje - niewykorzystany potencjał
Przez pięć lat rozwijania Przeprogramowanych nagraliśmy kilkadziesiąt godzin podcastów. Każda z rozmów zawiera mnóstwo treści, które doceniają nasi słuchacze - widzimy to w ocenach i łącznym czasie, jaki spędzacie przy naszych nagraniach. Niestety, do tej pory wszystkie rekomendacje, wiadomości i ciekawostki pozostawały w sferze audio. Postanowiliśmy to zmienić - okres wakacyjny to idealny moment na eksperymenty i inwestycje długoterminowe. Automatyzacja transkrypcji stała się więc jedną z inicjatyw na pierwsze tygodnie lipca.
Dzięki temu projektowi chcemy osiągnąć kilka celów:
- zwiększenie dostępności naszych treści
- poprawę pozycji w wynikach wyszukiwania
- dogłębne poznanie narzędzi no-code
W tym wpisie opiszę najważniejsze elementy całego projektu.
W drodze do MVP
Najważniejszym elementem całego procesu było rozpoznanie technologii, która będzie odpowiedzialna za tworzenie właściwych transkrypcji. To gdzie, kiedy i w jaki sposób je uruchamiać, było dla nas sprawą drugorzędną.
Rozpoczęliśmy od prawdopodobnie najpopularniejszego modelu AI, który pozwala konwertować mowę na tekst - OpenAI Whisper. Poprzez API możemy testować endpointy odpowiedzialne za transkrypcje oraz translacje nagranych rozmów właśnie z wykorzystaniem Whispera. Szybko okazało się, że ten model ma swoje ograniczenia:
- wielkość nagrania nie może przekraczać 25 MB (stan na lipiec 2024)
- model nie rozróżnia osób, które biorą udział w rozmowie (co jest kluczowe w naszych podcastach)
Korzystając z Whispera musielibyśmy więc procesować niezależne ścieżki audio od każdej z osób, które uczestniczą w nagraniu, a do tego kompresować pliki do odpowiednich rozmiarów. Nam zależało na uniknięciu dodatkowej pracy, więc kolejnym wyborem była platforma AssemblyAI.
AssemblyAI - nasz wybór
AssemblyAI to platforma, którą odkryłem dopiero w momencie budowania tego projektu. Dzięki publicznemu API możemy przesłać nagranie w formacie mp3, wav lub ogg i otrzymać gotowy plik tekstowy z transkrypcją. W przeciwieństwie do Whispera, AssemblyAI rozróżnia osoby, które biorą udział w rozmowie, więc dla twórców podcastów sprawdzi się idealnie.
Firma oferuje darmowy plan, który pozwala na przetworzenie 100 godzin nagrań, a także jednoczesne procesowanie pięciu równoległych zadań. W naszym przypadku to wystarczająca ilość danych - pozwoli nam ona zbadać jakość transkrypcji w języku polskim i zdecydować, czy warto zainwestować w płatny plan.
Dla programistów z ekosystemu JavaScript/TypeScript zaletą okaże się też fakt, że na npm znajdziemy oficjalne SDK, które ułatwia integrację z API.
Nasz kontakt z API skupił się na dwóch endpointach:
Dwa endpointy wpływają również na docelowy proces integracji, który rozbijamy na dwie części - w pierwszej zlecamy zadanie uzyskując transcriptionId, a w drugiej sprawdzamy stan transkrypcji i pobieramy gotowy plik tekstowy (jeśli już istnieje).
Obsługa zadań i przechowywanie zleceń
O ile jednostkowe transkrypcje można z powodzeniem zlecać i realizować lokalnie, tak do zautomatyzowania procesu potrzebujemy narzędzia, które będzie zarządzać zadaniami i stanem wszystkich operacji. W naszym przypadku wybór padł na Make w połączeniu z arkuszami Google Sheets.
Popularna usługa no-code oferuje dziesiątki gotowych integracji (również z AssemblyAI), które pozwolą nam na zbudowanie pełnego workflow - od pobrania plików audio, aż do zgłoszenia Pull Requestu na GitHubie z nową transkrypcją.
Pierwsza część procesu, czyli zlecanie transkrypcji, opiera się o trzy kroki:
- Upload nowego pliku audio na Google Drive, do obserwowanego przez Make folderu
- Uruchomienie scenariusza, który zleci transkrypcję na podstawie publicznego linku z GDrive
- Zapisanie otrzymanego transcriptionId, którego stan sprawdzimy w kolejnym kroku
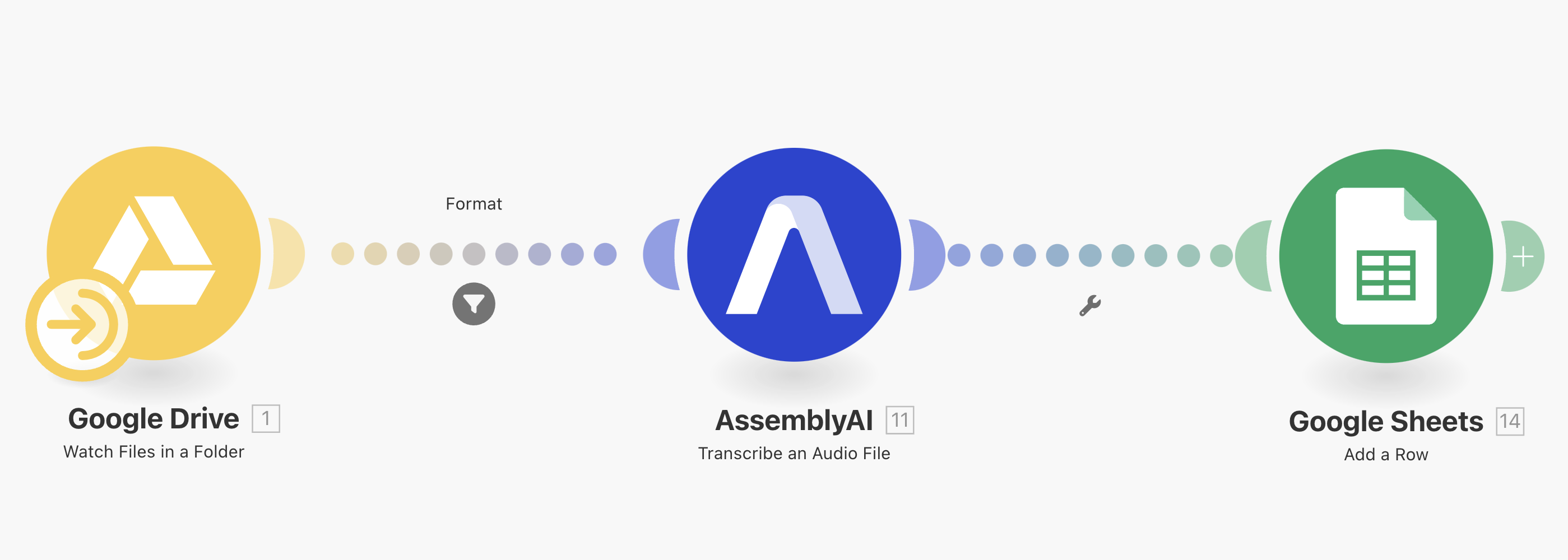
Wykonanie takiego zadania zakończy się nowym wpisem w arkuszu GSheets z informacją o transcriptionId oraz stanie zadania:
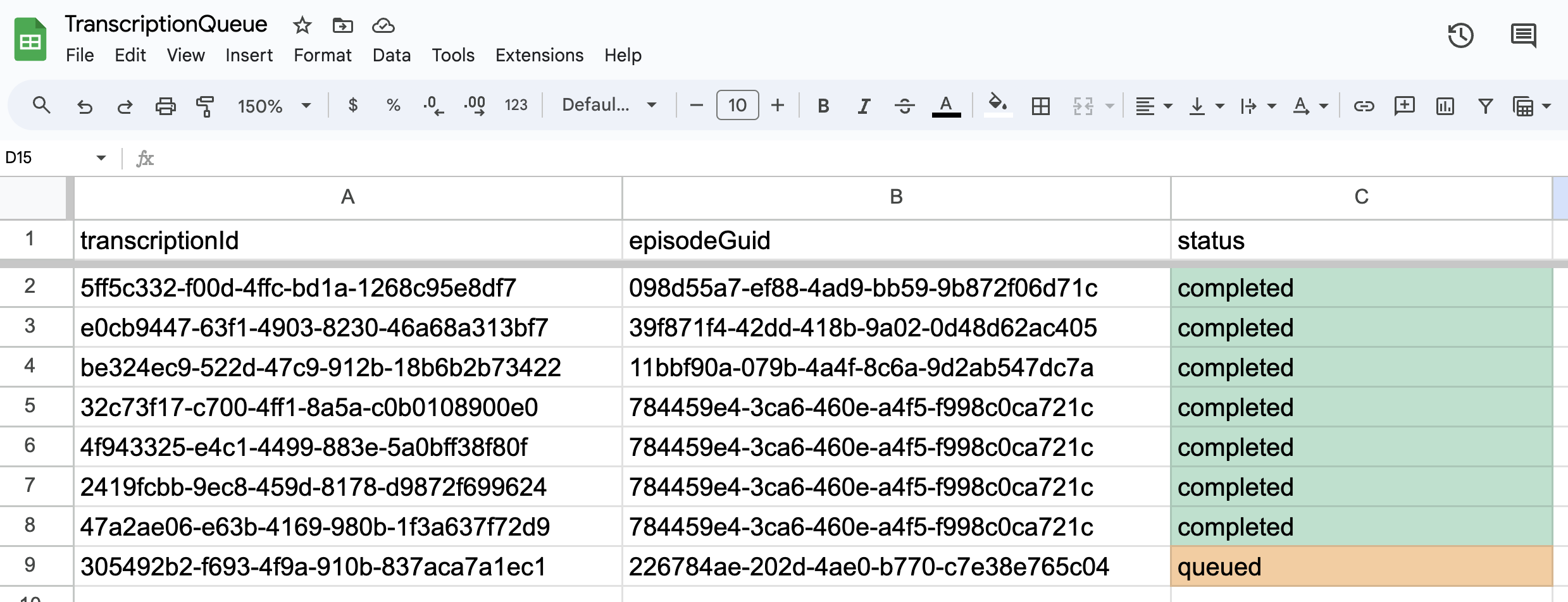
Każde zlecenie będzie na początku w stanie “queued”, a po zakończeniu przetwarzania zmieni się na “completed”. Dodatkowa kolumna, czyli episodeGuid to sposób na połączenie transkrypcji z identyfikatorem odcinka, który pobieramy z feedu RSS Spotify.
Ważne - przy tworzeniu zleceń, AssemblyAI musi być w stanie pobrać plik audio z publicznego linku. Folder musi być więc dostępny dla wszystkich, a plik nie może być zabezpieczony hasłem.
Odpowiadając na niezadane pytanie - dlaczego ten scenariusz nie ma swojej kontynuacji w postaci oczekiwania na zakończenie zadania?
Zdecydowaliśmy się na rozwiązanie rodem z systemów rozproszonych, gdzie asynchroniczna komunikacja nie blokuje przepływu danych. Dzięki temu oba elementy procesu, działające w różnym tempie, są od siebie niezależne, a my dla jednego zlecenia możemy wykonywać kilka pobrań, a także ustawiać dowolny harmonogram sprawdzania stanu zadań. Stay async.
Przetwarzanie transkrypcji
Krok drugi rozpoczyna się od sprawdzenia kolejki zadań w arkuszu Google Sheets. Dla wszystkich wierszy w statusie “queued” uruchamiany jest scenariusz, który poprzez SDK AssemblyAI sprawdza status transkrypcji. Jeśli dana transkrypcja jest gotowa, pobieramy jej treść i możemy ją przetwarzać w dowolny sposób.

Jak wygląda przetwarzanie otrzymanych danych?
Włączony tryb “Speaker Diarization”, czyli rozpoznawanie mówców, wpływa na format danych otrzymanych z AssemblyAI. Dla nas najważniejszy będzie obiekt utterances, czyli tablica z wypowiedziami każdej z osób biorących udział w rozmowie. Każda wypowiedź zawiera informacje o czasie rozpoczęcia, zakończenia, a także treść i etykietę mówcy.
{
"utterances": [
{
"confidence": 0.93,
"speaker": "A",
"start": 250,
"end": 26950,
"text": "Cześć, witamy w nowym odcinku podcastu Opanuj.AI!",
"words": [ ... ]
},
{
"confidence": 0.92,
"speaker": "B",
"start": 26950,
"end": 29982,
"text": "W tym odcinku przygotowaliśmy dla was trzy ważne tematy.",
"words": [ ... ]
},
]
}Poprzez Make możemy taką tablicę przetworzyć i połączyć w jeden łańcuch znaków. Posłuży nam do tego para narzędzi Iterator oraz Text Aggregator:
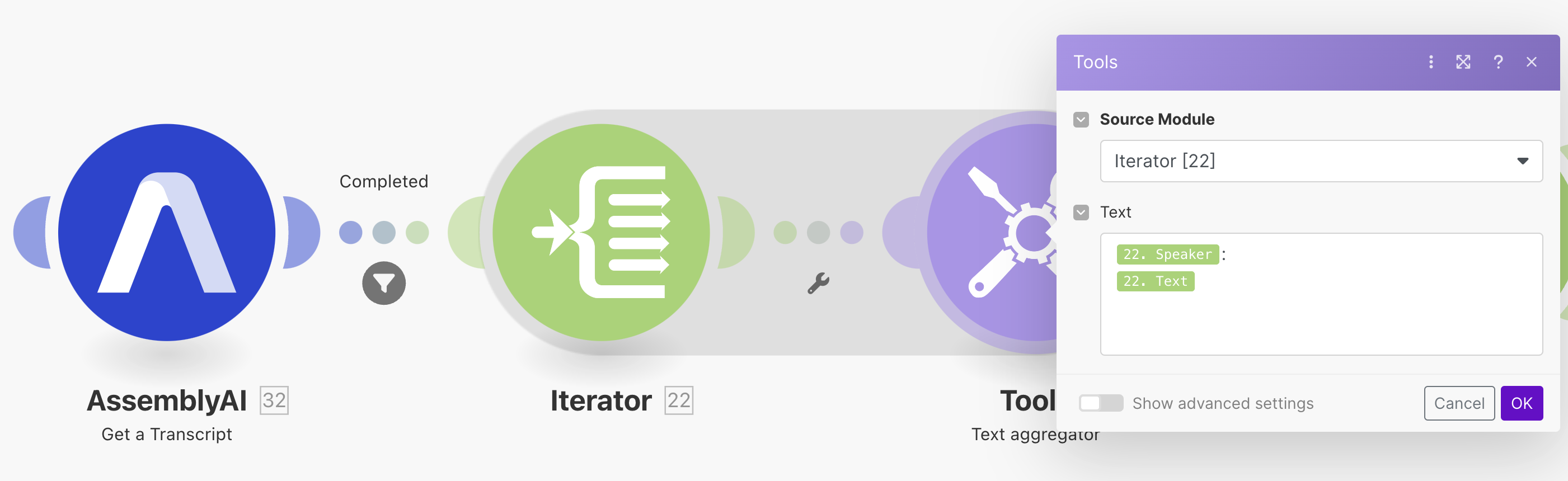
Na tym etapie mamy już jeden tekst, który możemy przesyłać w dowolne miejsce:
A:
Cześć, witamy w nowym odcinku podcastu Opanuj.AI!
B:
W tym odcinku przygotowaliśmy dla was trzy ważne tematy.
A:
Pierwszy z nich to...W kolejnym kroku zdecydowałem się na wykorzystanie routera, który pozwoli na zrealizowanie dwóch operacji:
- zapisanie transkrypcji w formie pliku tekstowego na Google Drive
- zgłoszenie Pull Requestu na GitHubie z nową transkrypcją
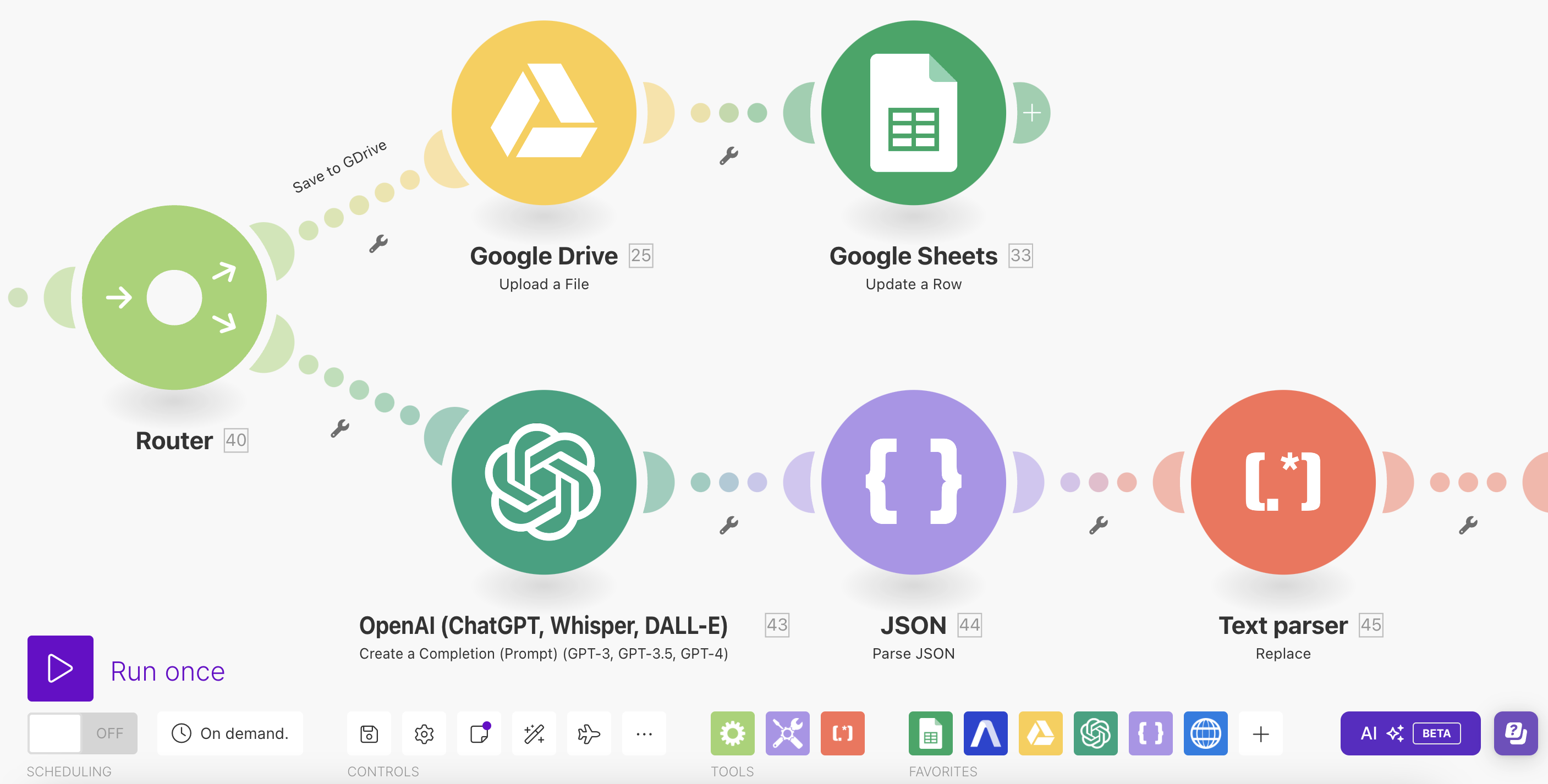
Pierwszy z nich raczej nie wymaga komentarza - a drugi?
Pełna automatyzacja procesu
Na tym etapie cała integracja była praktycznie na ukończeniu. Otrzymywaliśmy plik Markdown z transkrypcją podcastu i podziałem na mówców, który dodatkowo był zapisywany na Google Drive. Postanowiliśmy jednak pójść o krok dalej i zautomatyzować proces aktualizacji etykiet oraz wprowadzania transkrypcji do projektu, który stoi za stroną Opanuj.AI
Pierwszy krok to aktualizacja etykiet - zadanie realizuje dla nas model językowy OpenAI, którego instruujemy przez prompt systemowy:
Przekażę ci fragment transkrypcji podcastu.
Rozmowa prowadzona jest przez dwie osoby - ich imiona to Przemek i Marcin.
Wypowiedzi każdej z osób są oznaczane literami A (lektor pierwszy) i B (lektor drugi).
Na podstawie treści transkrypcji oceń, kto jest osobą A, a kto B.
Zwróć wynik w postaci JSON, gdzie pod kluczami A i B będą imiona lektorów.
Uwaga - w transkrypcji imiona mogą zawierać drobne literówki.Kolejnym promptem (z rolą User) jest krótki fragment oryginalnej transkrypcji, na podstawie którego model ma określić, kto jest kim. Wynikiem jest JSON z dwoma kluczami:
{
"A": "Przemek",
"B": "Marcin"
}Taki obiekt możemy wykorzystać w dedykowanych modułach Make, które podmienią etykiety w transkrypcji z liter, na imiona autorów podcastu.
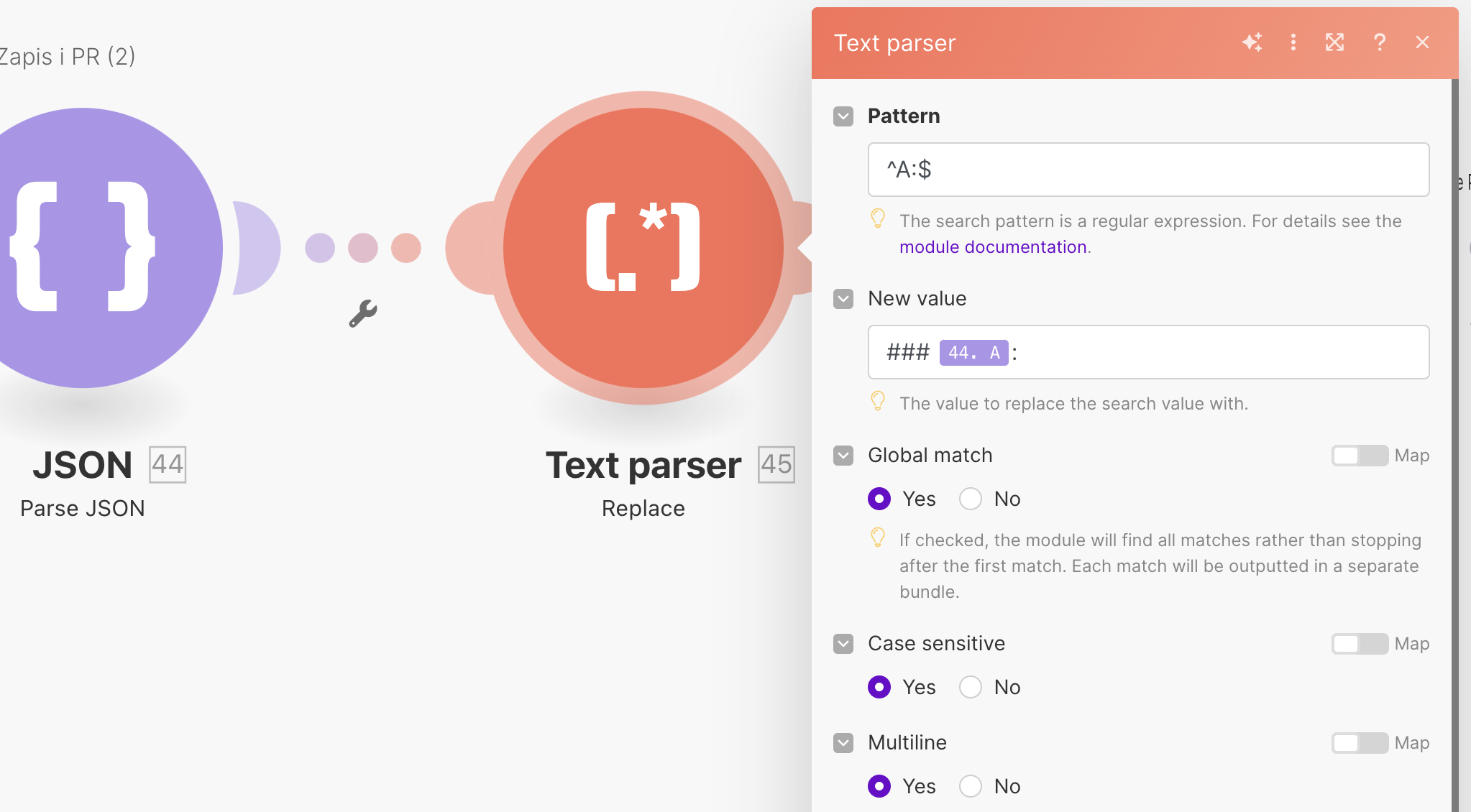
W dłuższej perspektywie ten krok może generować pewne błędy (szczególnie w kontekście rozpoznawania etykiet mówców) ale przy odpowiedniej konwencji otwierania podcastów, a także rosnącej jakości modeli językowych, powinniśmy być w stanie zminimalizować ryzyko błędów.
Zgłoszenie Pull Requestu
Ostatni element całego procesu to zgłoszenie Pull Requestu na GitHubie z nową transkrypcją. W naszym przypadku opieramy się o dostępne endpointy Github API, spośród których interesuje nas:
- założenie nowego brancha w repozytorium
- dodanie pliku Markdown z transkrypcją
- utworzenie Pull Requestu na podstawie nowego brancha
Te trzy operacje zawierają się w sekcjach API o nazwie Git database, Contents i Pull requests - link tutaj.
Na samym Make realizujemy to poprzez serię zapytań HTTP - nie wygląda to zbyt estetycznie, ale robi to, co powinno:

Największą zaletą takiego rozwiązania jest fakt, że wszelkie korekty możemy teraz wprowadzać tak jakbyśmy realizowali Code Review dla wirtualnego asystenta. Mamy dedykowany branch, pull request, a ostatnie zdanie w kwestii jakości należy do nas:
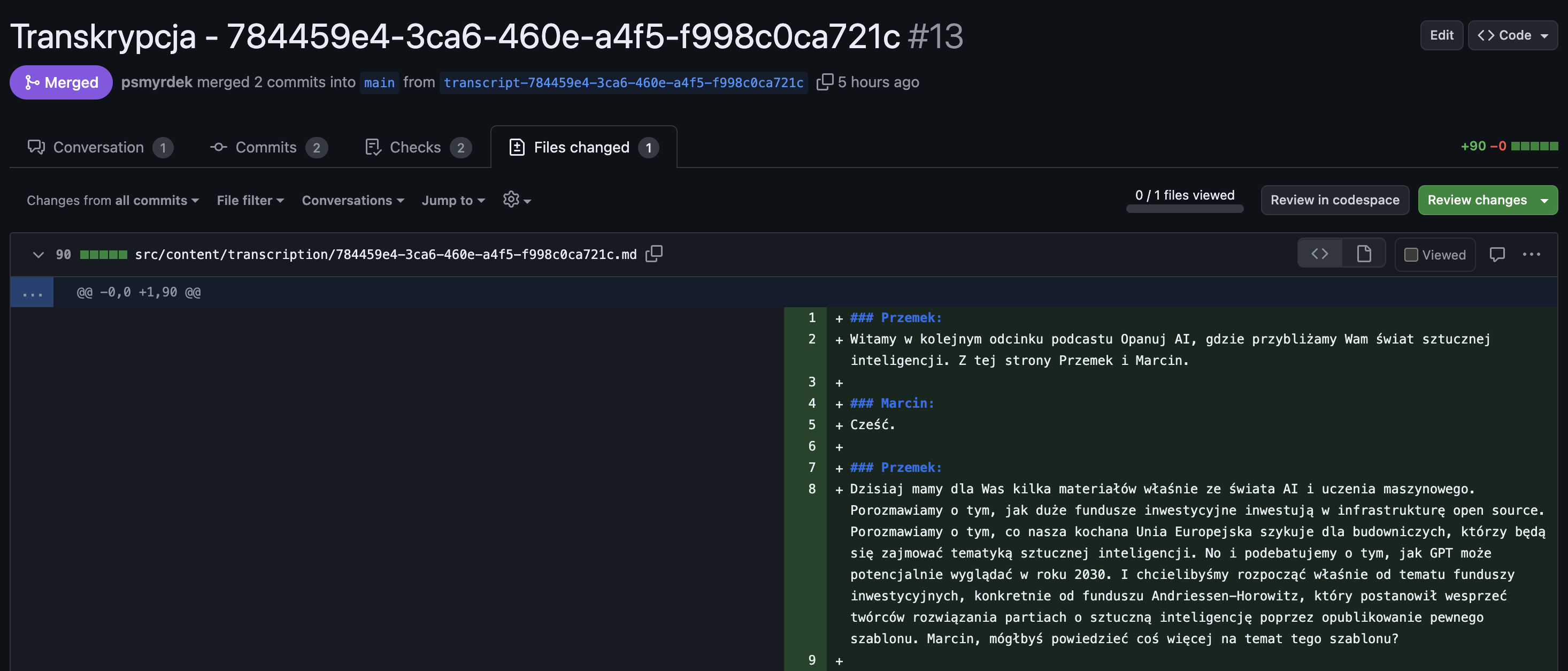
Dalsze kroki
Pierwsze podejście do automatycznego tworzenia transkrypcji przyniosło nam mnóstwo nowej wiedzy i wniosków, które wykorzystamy w kolejnych projektach.
W przyszłości będziemy mogli eksplorować dalsze rozszerzenia stworzonych scenariuszy, w tym parametryzację pod inne podcasty (np. z gośćmi), będziemy mogli porównywać modele i usługi odpowiedzialne za właściwe transkrypcje, a także badać koszty i zwrot z inwestycji, jaką jest zbudowana automatyzacja.
Zgodnie z założeniami, udało się zminimalizować liczbę ręcznych akcji, jakie trzeba wykonać do utworzenia transkrypcji. Na teraz takimi operacjami są jedynie:
- upload audio na Google Drive
- ręczne uruchamianie drugiego scenariusza w Make (co jednak daje nam to kontrolę nad procesem)
- przegląd i akceptacja Pull Requestu na GitHubie
Wszystkie inne operacje są wykonywane automatycznie, a pierwsze podcasty na naszej stronie mają już dodane transkrypcje. Jeśli chcecie poznać szczegóły tego procesu, zapraszam do dyskusji oraz wiadomości na [email protected]. Zachęcam też do zapisania się na newsletter Opanuj.AI, dzięki czemu co poniedziałek otrzymasz 3 wartościowe materiały ze świata AI/ML.