ML in PL 2023, czyli ile końca świata w świecie uczenia maszynowego?

TL;DR
Zdanie "Skynet has to wait", które padło z ust jednego z uczestników panelu "Human in the loop", dobrze podsumowuje nastroje uczestników wydarzenia.
Konferencyjna niewiadoma
Wchodząc do Centrum Nauki Kopernik, w którym odbywała się warszawska konferencja “ML in PL 2023”, miałem mieszane uczucia. Z jednej strony, po dziesiątkach konferencji na temat web developmentu w jakich brałem udział, miałem spore oczekiwania co do nowego rodzaju wydarzenia. Z drugiej strony pojawiły się też obawy - ile formalnego, akademickiego przygotowania będzie potrzebne, aby nie utonąć w przekazywanych treściach?
Kolejne siedem godzin miało mi pokazać, czy tego typu wydarzenia będę mógł odwiedzać częściej.
Nowe perspektywy
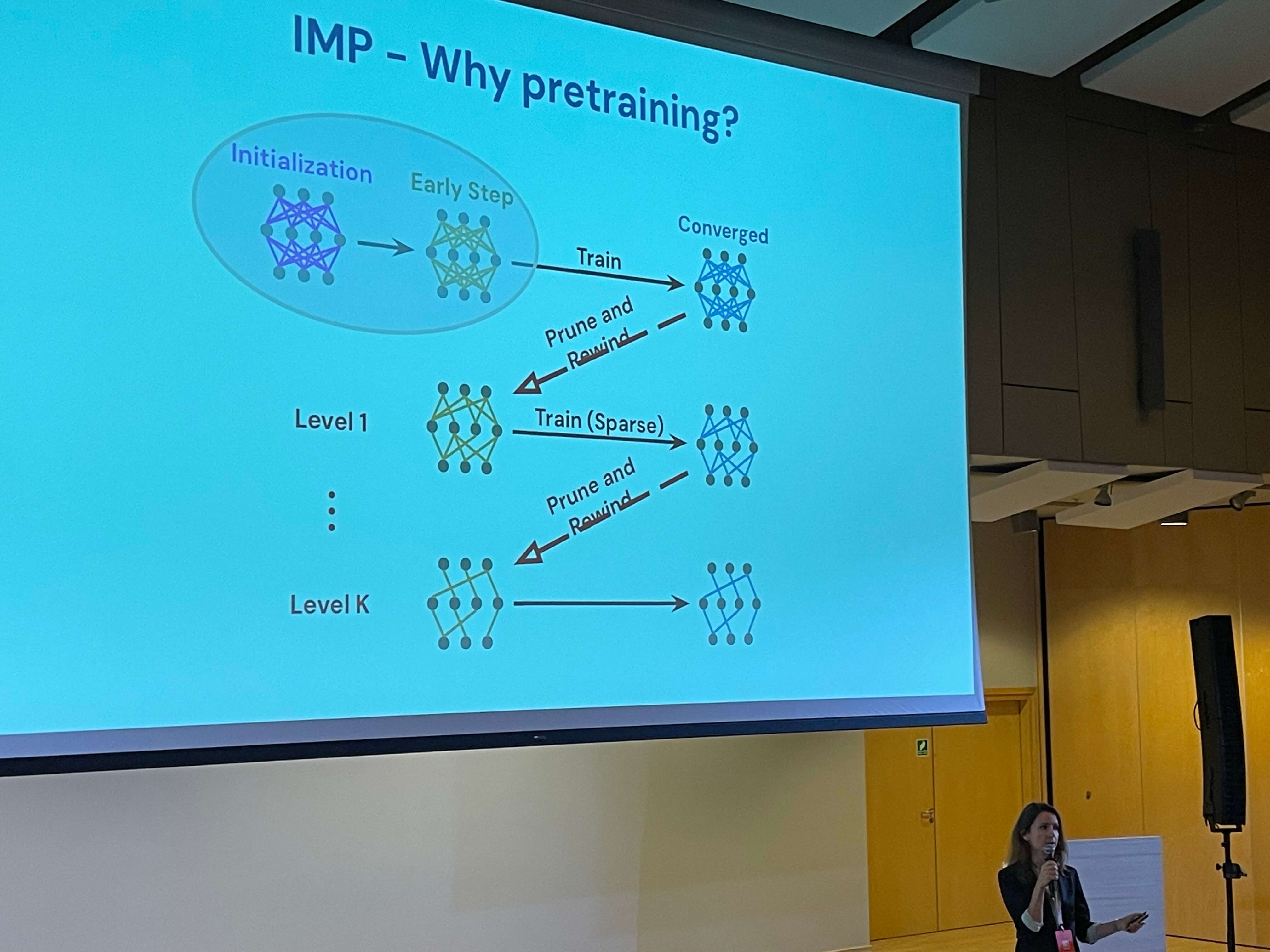
Moja ścieżka na konferencji rozpoczęła się od prezentacji Gintare Karolina Dziugaite (Google DeepMind) na temat Iterative Magnitude Pruning (IMP). Było to dla mnie pierwsze zetknięcie z tym zagadnieniem, ale samo wystąpienie okazało się zdecydowanie trafnym wyborem.
Iterative Magnitude Pruning to (dość kosztowna) technika optymalizacji modeli neuronowych, polegająca na iteracyjnym usuwaniu wag o najmniejszej wartości bezwzględnej na przestrzeni procesu budowania i trenowania modelu. Dzięki temu można znacząco zredukować rozmiar modelu bez dużego wpływu na jego skuteczność. Autorka przedstawiła tę koncepcję w przystępny sposób, podkreślając jej znaczenie w kontekście efektywności i oszczędności zasobów, co jest kluczowe w praktycznych zastosowaniach AI. Prelekcja przekonała mnie, że dalsze eksplorowanie tematyki mniejszych modeli językowych jest inwestycją wartą poświęcanego czasu (wbrew sugestiom, które przeczytałem pod swoim filmem kilka dni temu).
Po naprawdę przekonującym wstępie konferencja przeszła do etapu “contributing talks” - serii mniejszych, uzupełniających się prezentacji dotyczących bezpieczeństwie w świecie ML. Autorzy - Franziska Boenisch, Adam Dziedzic i Jan Dubiński przedstawiali kolejno tematy uczenia federacyjnego, zabezpieczeń w wielkich modelach językowych oraz sposobu na generowanie dodatkowych kosztów dla atakujących. Pierwszy raz spotkałem się z taką formą organizowania jednego bloku konferencji i przyznam, że ten fragment był dla mnie nieco zbyt intensywny - warto byłoby rozważyć chwilę oddechu pomiędzy prezentacjami a także kilkanaście dodatkowych minut dla prelegentów.

Ostatnim fragmentem przed przerwą obiadową był panel “Human in the Loop”, gdzie kolejni uczestnicy dzielili się swoim obserwacjami na temat współpracy ekspertów domenowych i algorytmów ML. Przykładami takich zadań są np. weryfikacja wyników klasyfikacji, oznaczanie danych czy modelowanie samej domeny problemu. Wnioski, które zanotowałem, sprowadzały się do zdania wypowiedzianego przez jednego z uczestników - “Skynet has to wait”. Współpraca ludzi i maszyn na zewnątrz bańki mediów społecznościowych wygląda zdecydowanie mniej apokaliptycznie, niż mogłoby się wydawać.

Drugą połowę dnia spędziłem na prelekcjach o wykorzystywaniu LLMów w astronomii (AstroLLaMa), algorytmach dyfuzji (DALL-E, Midjourney), a także na najbardziej wyczekiwanych przeze mnie talkach od prelegentów z Allegro i Mety. I właśnie ta część konferencji, łącząca światy biznesu i wiedzy naukowej, była dla mnie najciekawsza.
Na styku biznesu i akademii
Konferencje takie jak “ML in PL” oferują możliwość zrozumienia, jak szeroki zakres tematów można pokryć pod jednym, wspólnym hasłem “uczenie maszynowe”. Dla entuzjastów teoretycznych aspektów, takich jak architektury sieci neuronowych czy algorytmy optymalizacyjne, jest to okazja do zgłębienia najnowszych osiągnięć w dziedzinie ML. Jednocześnie, dla osób takich jak ja, bardziej zorientowanych na praktyczne zastosowanie nowych technologii, jest to przestrzeń do inspirowania się kolejnymi osiągnięciami na styku biznesu i uczelnianych laboratoriów.
Jedną z takich praktyczno-teoretycznych prezentacji, która wzbudziła szczególnie duże zainteresowanie, była ta dotycząca Toolformera. Toolformer to model na bazie GPT-J, wytrenowany przez inżynierów firmy Meta, który na skutek obsługi narzędzi takich jak kalkulator, kalendarz czy słownik faktów zaczął wykazywać obiecujące rezultaty w popularnych benchmarkach testujących LLMy. Poza przedstawieniem rezultatów pracy swojego zespołu, autorka wystąpienia (Jane Dwivedi z Meta AI), pokazała również kilka sposobów na poprawianie działania modeli językowych, w tym ogólny opis metody RAG, współpracę kilku modeli w ramach jednego zadania, no i finalnie samych narzędzi, czyli integrowania zewnętrznych API z całością systemu opartego o LLM.

Zarówno przedstawicielka Mety, jak i Piotr Stachowicz, VP R&D w edrone, z którym dyskutowałem w przerwie, zwracali uwagę na to, że jeszcze sporo czasu upłynie zanim uzyskamy pełną produkcyjną niezawodność takich rozwiązań (co potwierdzi każdy, kto testował pluginy w ChatGPT). Ostateczne jest to wniosek pozytywny - zamiast naiwnego huraoptymizmu można skupić się na kontynuacji prac nad modelami obsługującymi złożoność otaczającego nas świata.
Druga ze wspomnianych przeze mnie prezentacji, przygotowana przez zespół Allegro, skupiała się na wdrażaniu “ML at reasonable scale”. Piotr Januszewski i Marcin Cylke zapewniali, że nie będąc Googlem, Metą, czy OpenAI, uczenie maszynowe wciąż może przynosić solidne zwroty dla biznesu, czego przykładem są systemy rekomendacji i bardziej zaawansowane techniki utrzymania klienta. Inspiracją działań prelegentów jest Jacopo Tagliabue, którego projekty możecie śledzić w tym miejscu.
Konferencyjne tl;dr
Moje notatki z konferencji sprowadzają się do następujących punktów (co widzieli już śledzący nasz profil na Instagramie):
- bez obaw - nie musisz być doktorem, lub w trakcie doktoratu, aby nie utonąć na ML in PL
- eksperymentuj z małymi modelami językowymi - for fun and for profit
- generatywna AI zostanie z nami na dłużej - to okazja dla początkujących na zdobycie nowej wiedzy o dużym potencjale w kontekście przyszłego rynku pracy
- jeśli dotknęło cię AI-FOMO, wyłącz media społecznościowe - progress w świecie ML jest imponujący, ale na koniec dnia to po prostu obszar informatyki, który możesz eksplorować w swoim tempie
- patrząc globalnie, dzięki dostępnej infrastrukturze oraz nagromadzeniu talentów, state-of-the-art robią firmy z USA, ale zamiast kompleksów warto poszukać swojego mikro-kawałka tortu i spróbować z niego wyciągnąć ile się da
Niestety, w tym roku miałem okazję zobaczyć jedynie 25% całego czterodniowego wydarzenia, ale w przyszłym roku chciałbym ten wyniki co najmniej podwoić. Konferencja okazała się być świetną okazją na spojrzenie na świat Machine Learningu z perspektywy naukowej, biznesowej i społecznej, co skutecznie zredukowało moje FOMO i zachęciło do dalszej eksploracji tej tematyki. Zdecydowanie polecam wizytę na ML in PL 2024!
(Powyższa rekomendacja uczestnictwa nie była przedmiotem płatnej współpracy, a jest wyłącznie podsumowaniem osobistych doświadczeń. Organizatorom serdecznie dziękujemy za udostępnienie wejściówek na konferencję.)