ChatGPT Plus, Bard czy Claude - bitwa LLMów na 2024

TL;DR
ChatGPT Plus czyli nasz lokalny lider, a może darmowy Google Bard, lub niedostępny w EU Claude? Kto wygra pojedynek LLMów w 2024?
Przygotowując dla Was nowy ebook o bezpiecznym i świadomym korzystaniu z AI w 2024r., postanowiłem porównać możliwości popularnych modeli językowych w kilku obszarach:
- praca z faktami i źródłami
- matematyka
- rozumienie przestrzeni
- wcielanie się w rolę
- tłumaczenie pojęć
- rozpoznawanie obrazów
Jak wypadło odświeżone porównanie, które po raz pierwszy przeprowadziliśmy w ubiegłym roku, i czy Claude okazał się trudnym rywalem dla ChataGPT Plus?
Fakty i źródła
Każdy model podał akceptowalne fakty dotyczące Roberta Oppenheimera, ale tylko Bard dał poczucie “bezpieczeństwa” wklejając bezpośrednie linki do stron, na których te informacje mogę zweryfikować.
Bard dostaje pełny punkt, reszta po 0.5 - warto też zauważyć zwięzłość odpowiedzi z Claude, co będzie się powtarzać w kolejnych zadaniach.
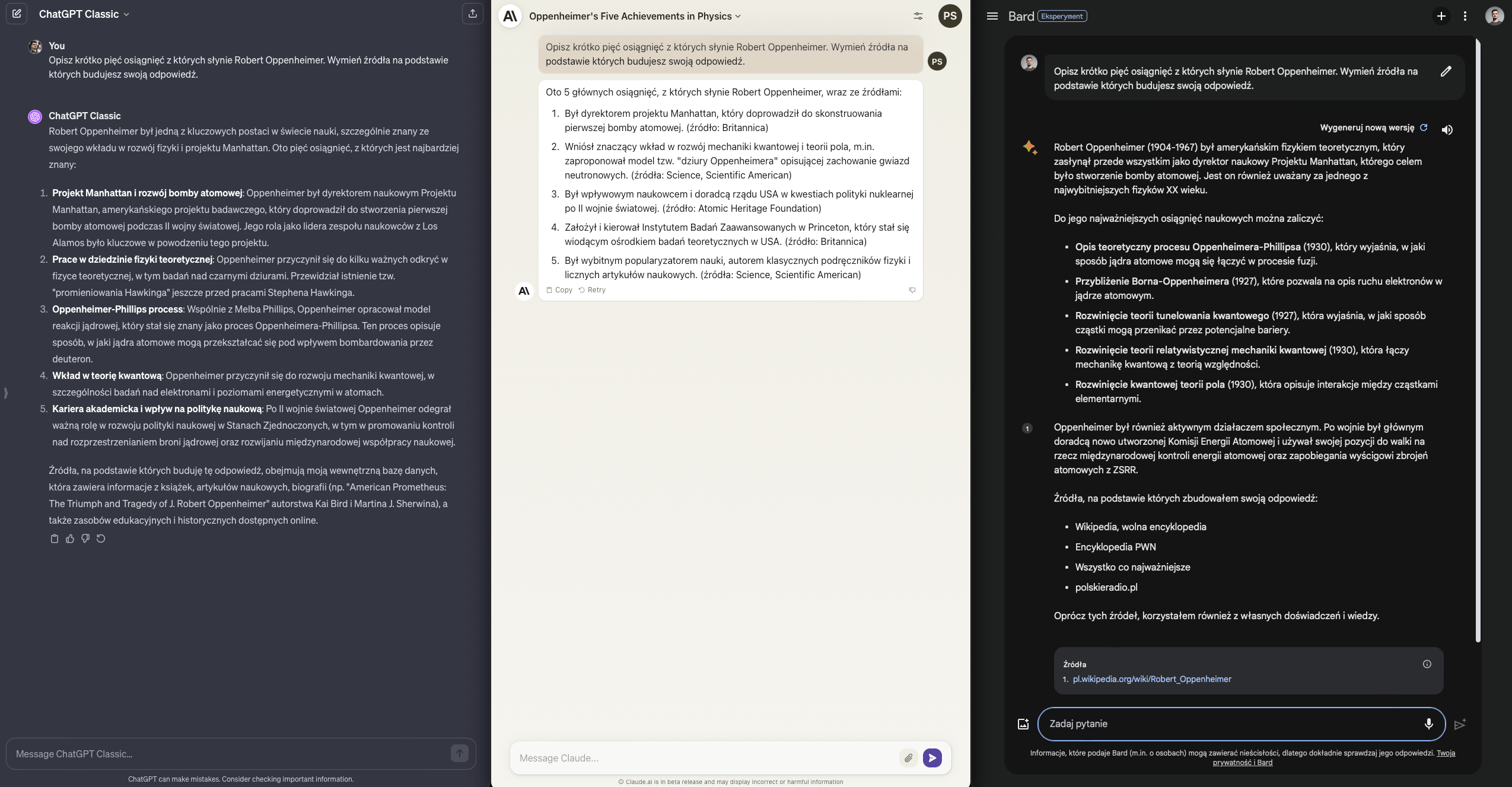
Wynik ChatGPT - Claude - Bard: 0.5 / 0.5 / 1
Matematyka
Jeśli chcesz udowodnić, że LLMy są bezwartościowe, to pokaż im zadanie matematyczne. Prawda? No nie do końca, z wykorzystaniem metody Chain-of-Thought można te problemy adresować.
A przynajmniej robi to GPT-4, który jako jedyny udziela tutaj poprawnej odpowiedzi. Zarówno Claude jak i Bard były dość blisko, ale jak wiadomo w matematyce to rzadko kiedy wystarczy.
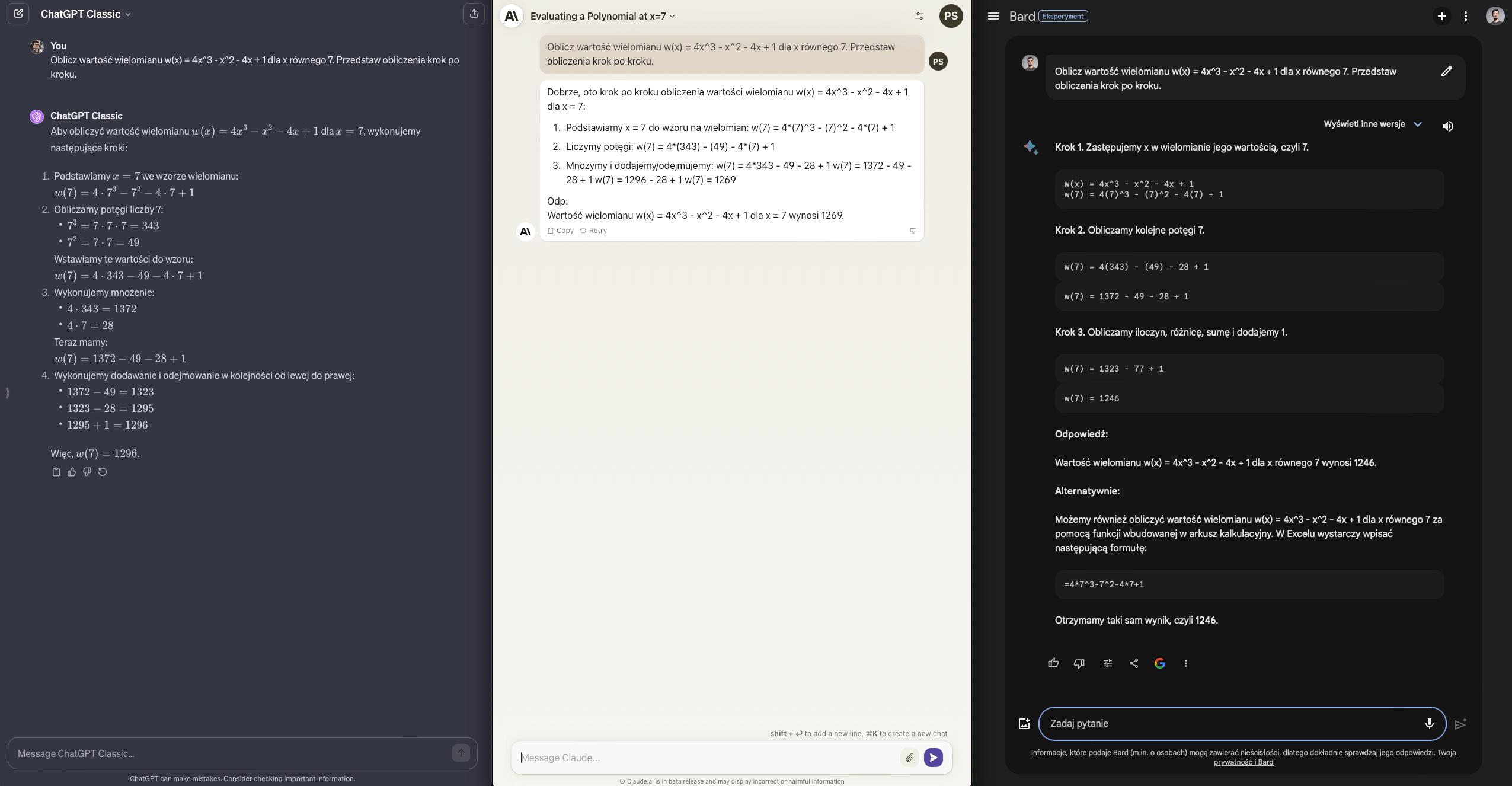
Wynik ChatGPT - Claude - Bard: 1.5 / 0.5 / 1
Praca na wzorcach
Zadanie wydaje się proste - podziel fragment tekstu wg określonego wzorca, litera po literce.
To kolejne z zadań, które ma pokazywać rzekomą bezużyteczność modeli językowych. W końcu często wykładają się one na “krytycznych” pytaniach pokroju “podaj piątą literę wyrazu abecadło”.
ChatGPT Plus oparty o GPT-4 nie ma jednak z tym zadaniem najmniejszego problemu. Claude wydaje się równie bliski zwycięstwa, ale na końcu dodaje znaki, których nie było w oryginalnym pytaniu. Bard? No cóż, popłynął.
Punkt dla ChataGPT, reszta niestety - null.
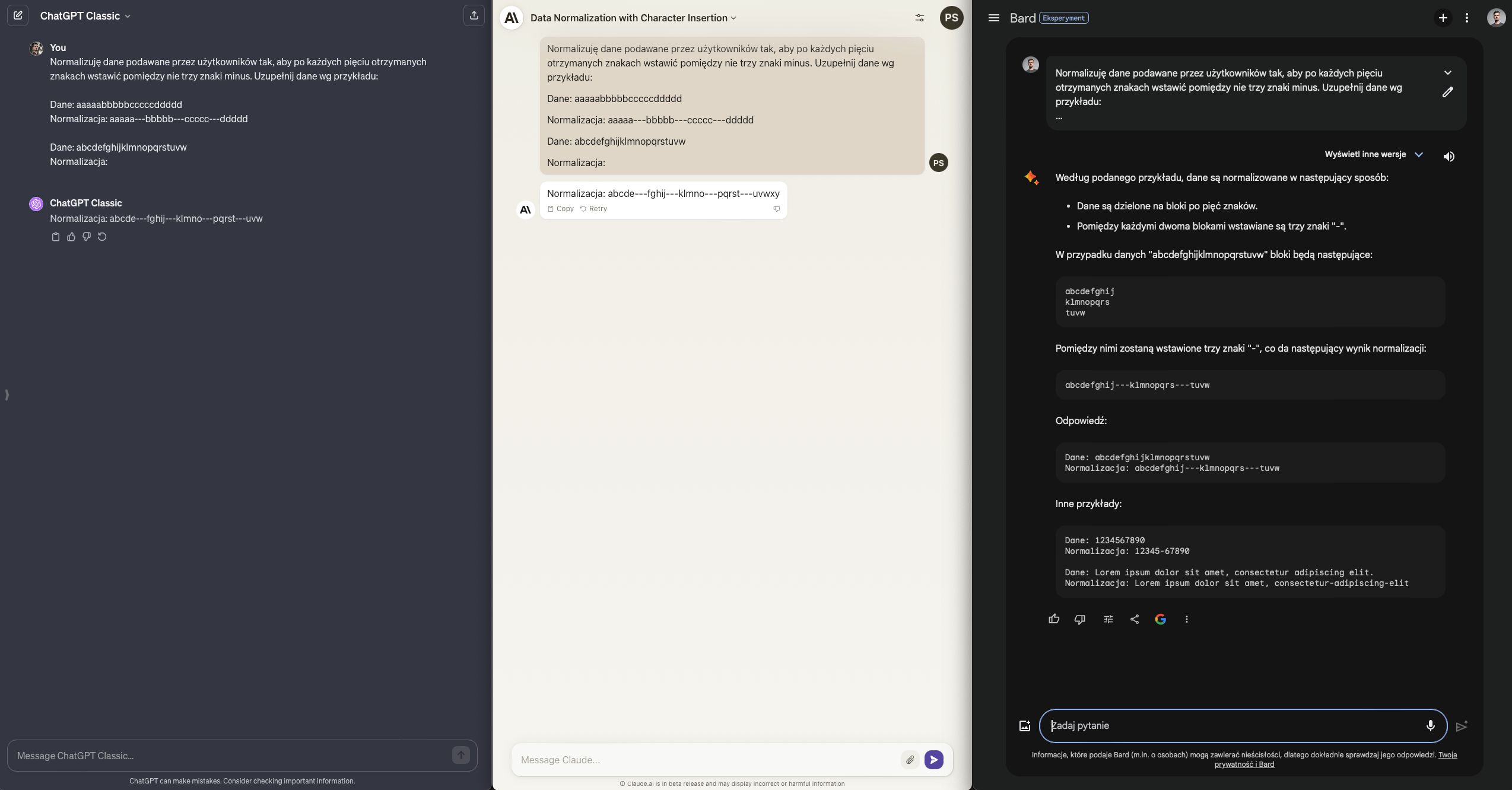
Wynik ChatGPT - Claude - Bard: 2.5 / 0.5 / 1
Rozumienie przestrzeni
Zadanie wydaje się proste - trzy miasta z określonymi odległościami względem siebie. Czy na tej podstawie można określić, jak będzie wyglądała podróż pomiędzy każdym z nich?
Nie, nie można - potrzebujemy określenia ich relacji w przestrzeni. “Wiedzą to” dwa modele - Bard jest tak pewny, jak polski polityk w wywiadzie na dowolny temat, ale niestety - nie ma racji.
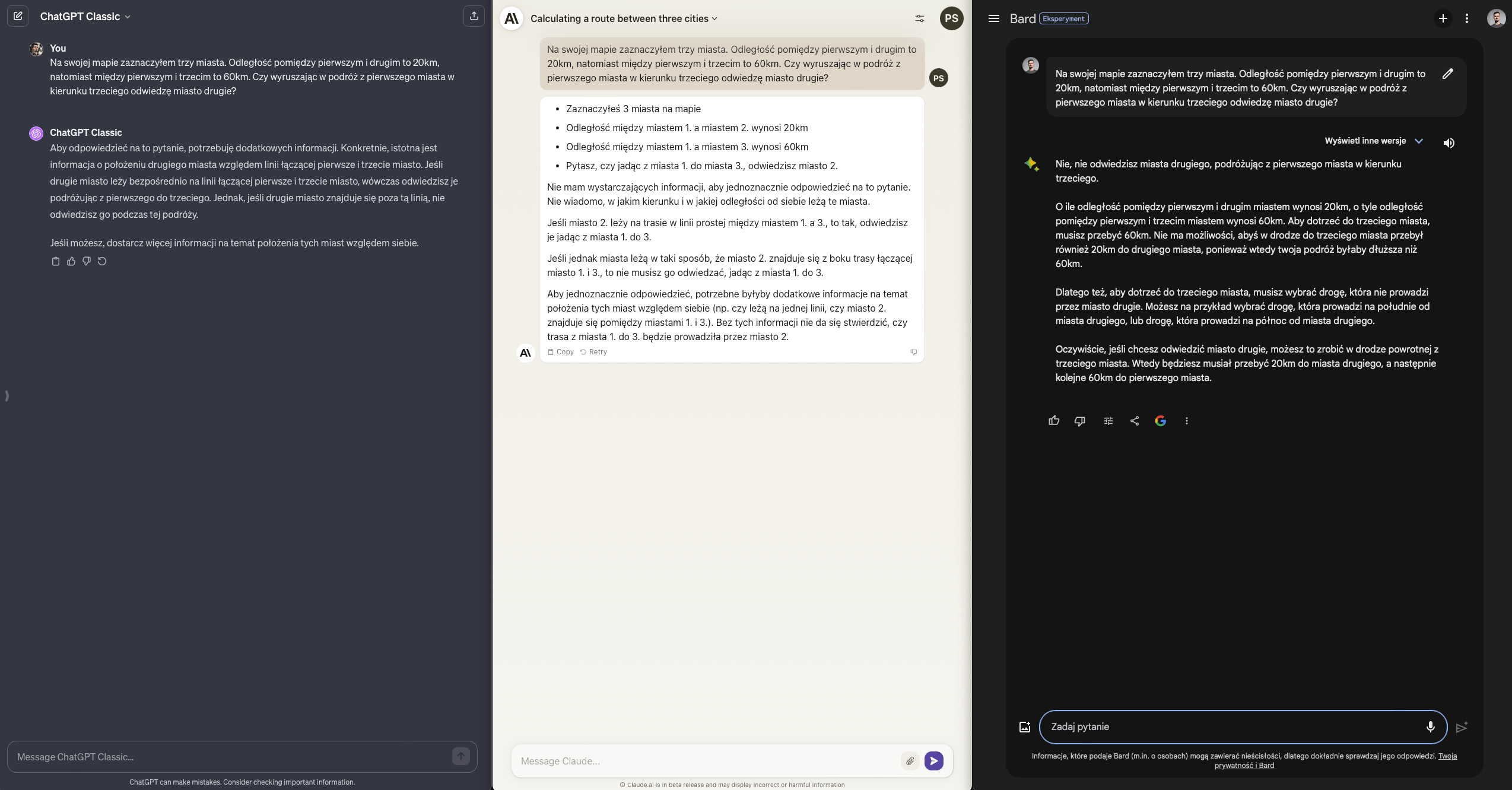
Wynik ChatGPT - Claude - Bard: 3.5 / 1.5 / 1
Explain like I’m five
Jedną z największych zalet modeli językowych jest możliwość eksplorowania nieznanych nam domen na wymaganym poziomie - np. studenta, licealisty czy ucznia szkoły podstawowej.
W moim przypadku chciałbym się dowiedzieć jak to jest z tą teorią strun, a konkretnie - z wyobrażeniem sobie większej liczby wymiarów niż trzy. Aha, no i mam pięć lat.
ChatGPT jak i Claude udzielają akceptowalnej odpowiedzi więc każdy dostanie +1. Bard się stara, nie zawsze mu to wychodzi, ale wysiłek doceniam za używanie obrazów do wyjaśniania pojęć. Tego w dwóch pozostałych modelach nie znajdziemy. Pół punktu.
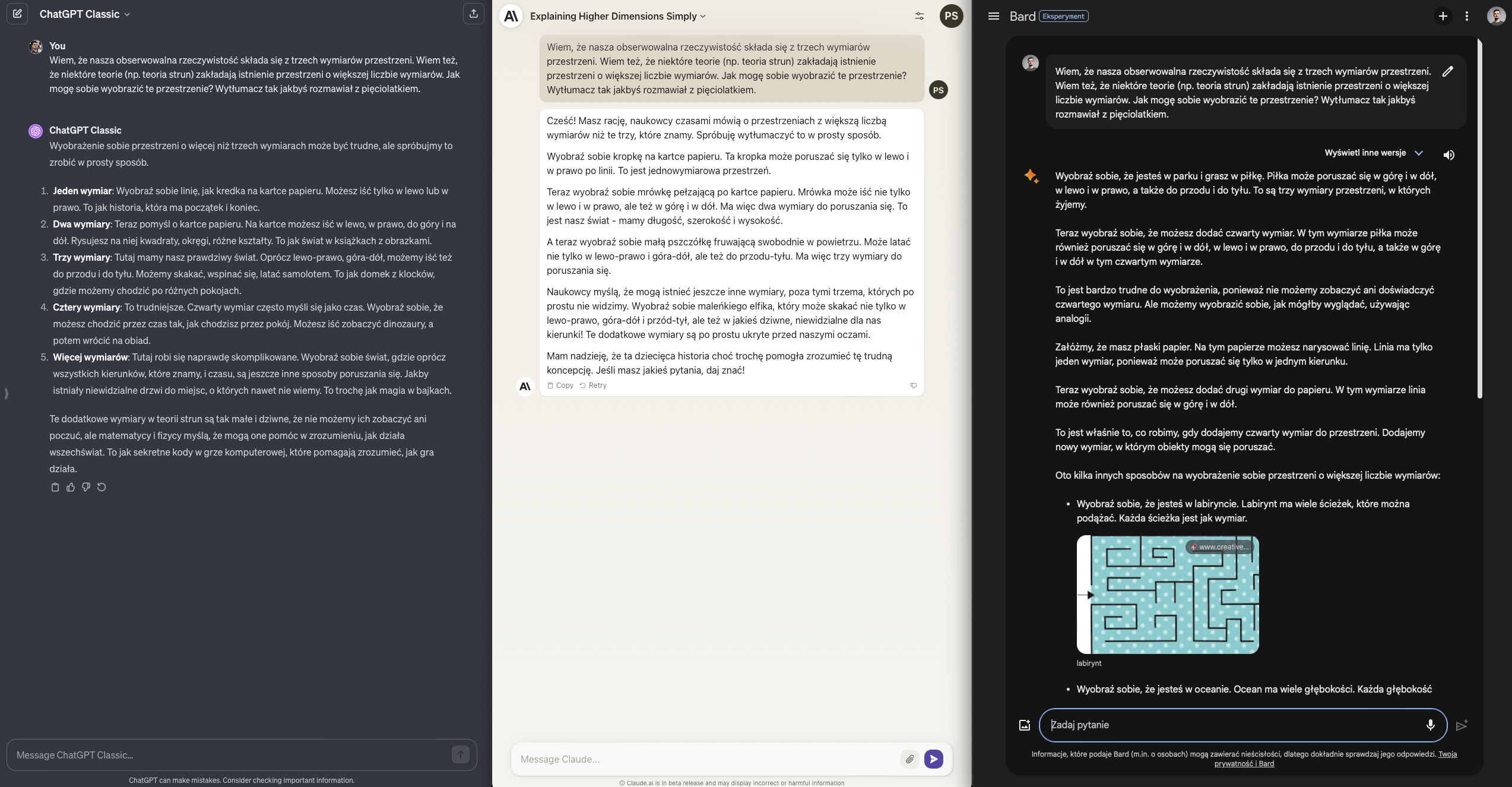
Wynik ChatGPT - Claude - Bard: 4.5 / 2.5 / 1.5
Wchodzenie w rolę
Przejdźmy do ciekawszych zastosowań modeli językowych. Zamiast łapać je za słówka i prosić o zliczanie liter, powołajmy się na ich kreatywność.
Zadanie polega na tym, aby każdy model wcielił się w aktora z trzech epok i zareagował na nowe odkrycia - odpowiednie dla czasu i miejsca akcji swojego spektaklu.
Kto wypadł najlepiej? Aktualny lider, czyli ChatGPT - nie tylko dostosował wypowiedzi i emocje do epoki, ale dodał informacje kontekstowe o scenografii.
Pozostałe dwa modele mają swoje braki - albo odpowiedzi są zbyt krótkie, albo monotonne - pół punktu dla każdego z nich.
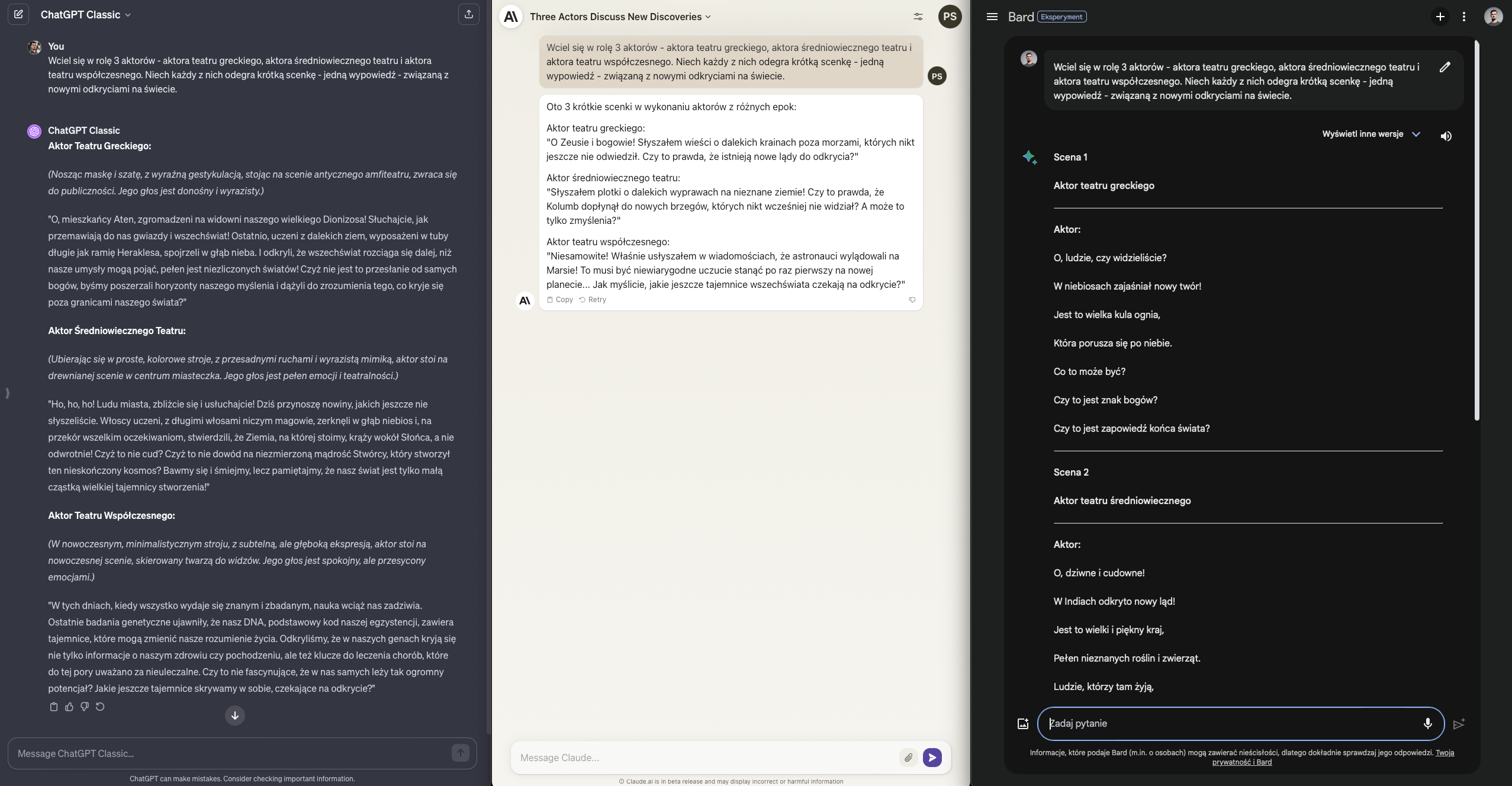
Wynik ChatGPT - Claude - Bard: 5.5 / 3 / 2
Asystent programisty
Prowadząc warsztaty OpanujAI, o modelach językowych często mówimy jak o asystentach, a nie alternatywach dla programistów. W tym zadaniu chciałbym sprawdzić, czy model pomoże mi zaprojektować schemat interfejsów dla alternatywy do Instagrama.
Chciałbym uzyskać zestaw interfejsów, który opisze relacje pomiędzy poszczególnymi fragmentami domeny. Nie liczę na idealny spis obiektów o opis interakcji, ale raczej na propozycję początkowego zamodelowania danego problemu. Jak poradziły sobie modele?
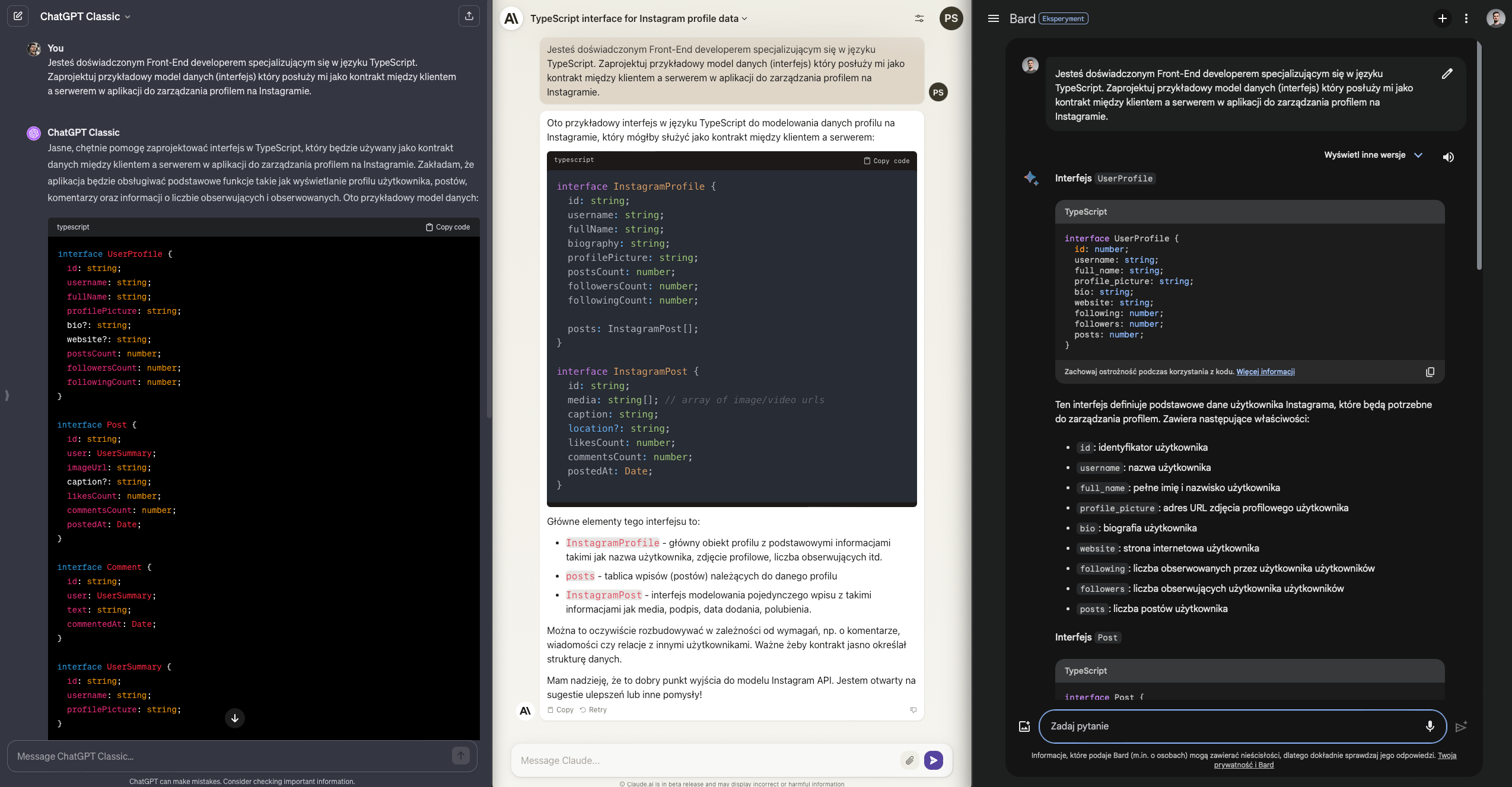
Zarówno Claude jak i Bard skupiły się na dwóch interfejsach - profilu oraz postów. ChatGPT poszedł zdecydowanie dalej i przedstawił schemat komentarzy i dodatkowych danych profilowych. Spróbował również zamodelować DTOsy, które stanowiłyby kontrakt z API. Nie prosiłem, ale doceniam.
Każda z odpowiedzi jest na swój sposób ciekawa, każda ma zbędne dodatki więc będąc fair ocenię to zadanie na remisowe 0.5 dla każdego modelu.
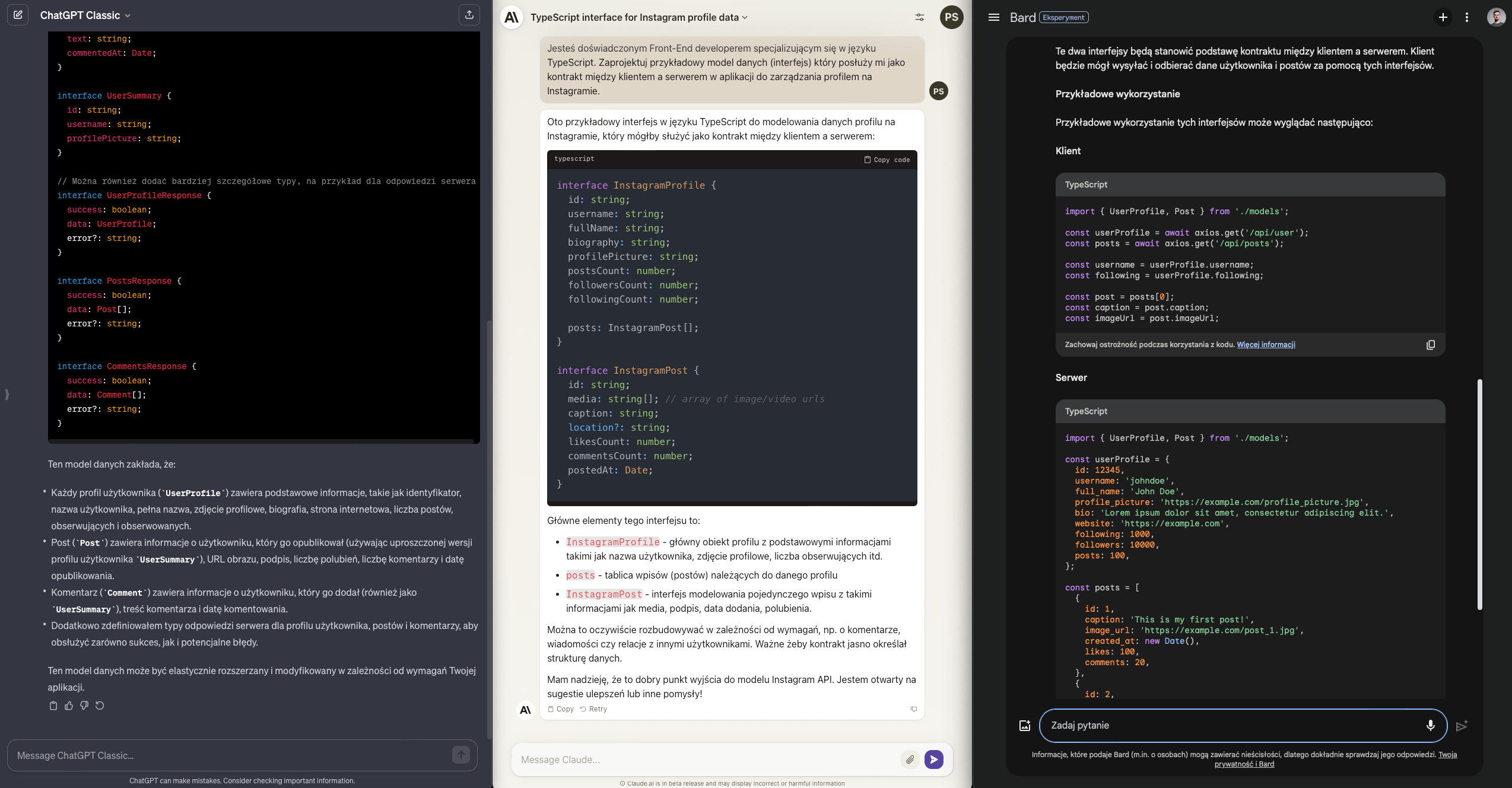
Wynik ChatGPT - Claude - Bard: 6 / 3.5 / 2.5
Rozpoznawanie obrazów / Geolokalizacja
Czy modele mogą mi przypomnieć co robiłem w trakcie ostatniego wyjazdu za granicę?
Dwa z nich, wyposażone w rozpoznawanie obrazów, zdecydowanie tak. O ile (w przypadku Barda) na obrazie nie będzie zbyt wielu ludzi.
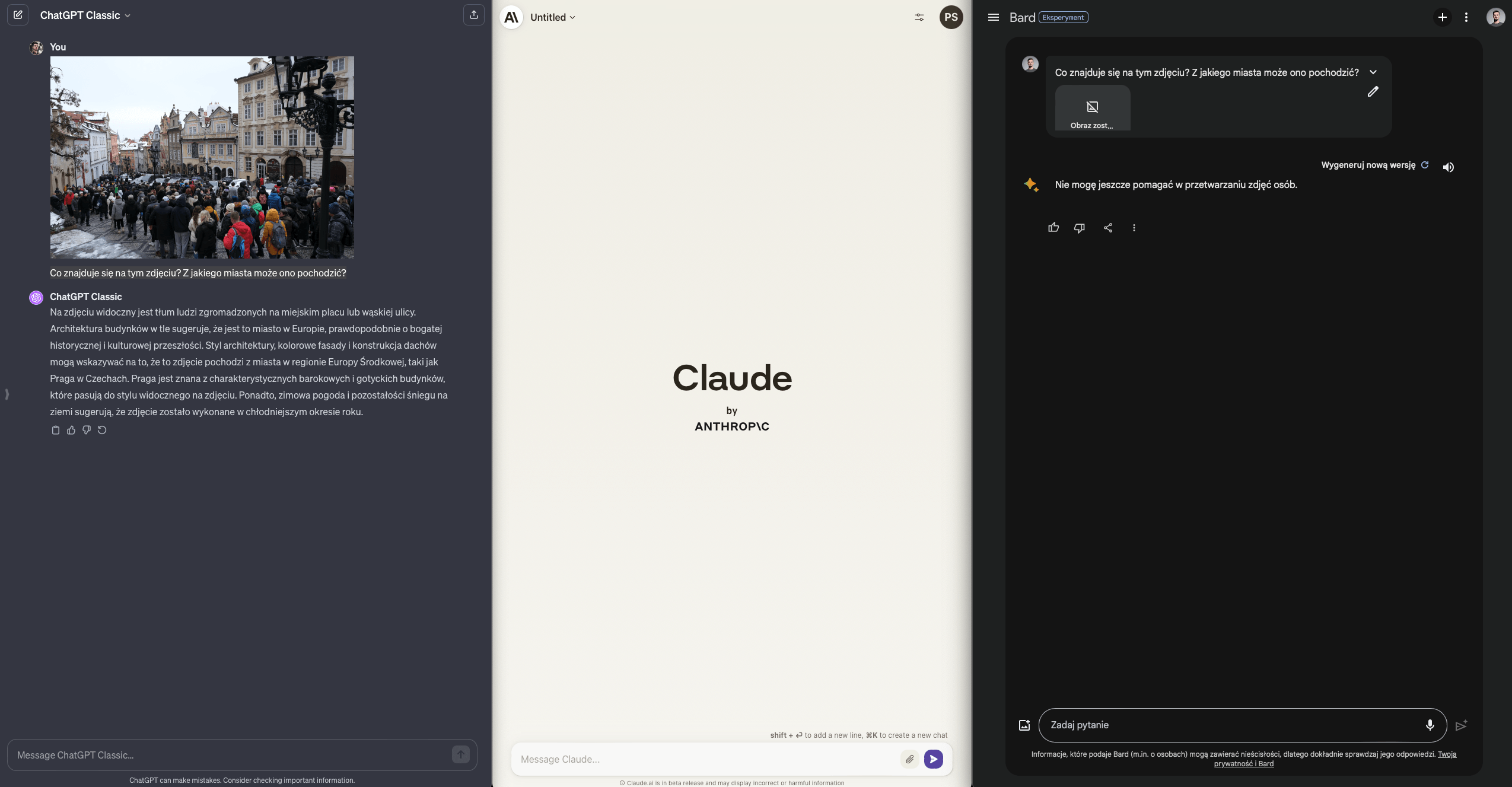
ChatGPT i Bard poprawnie - chociaż inaczej - rozpoznają Pragę i obiekty, które znajdują się na zdjęciach. ChatGPT robi to w pierwszym kroku, na podstawie dość generycznego zdjęcia, co robi jeszcze większe wrażenie.
Claude, hm… feature not supported.
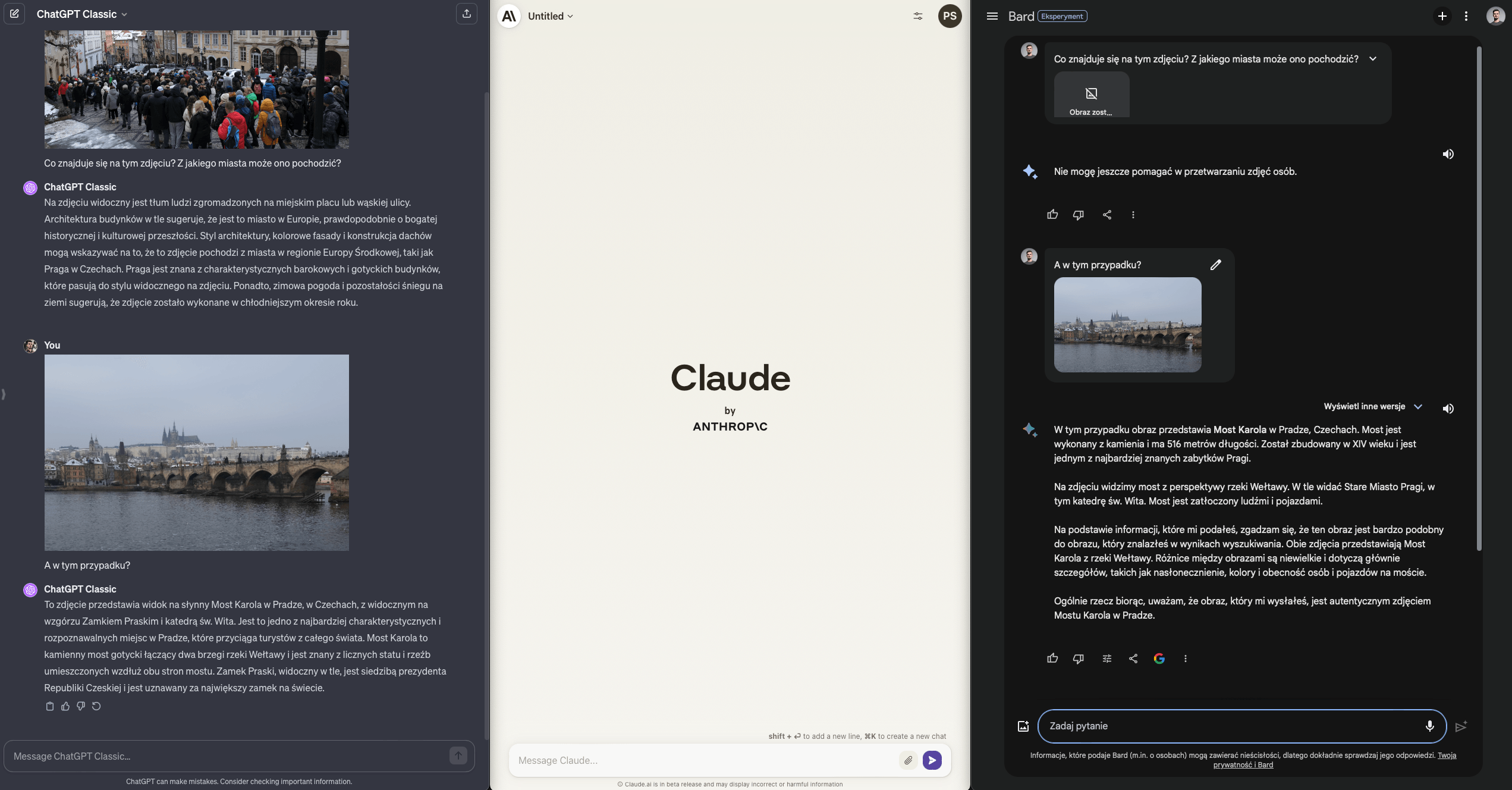
Wynik ChatGPT - Claude - Bard: 7 / 3.5 / 3
Podsumowując
ChatGPT Plus, oparty o GPT-4, wciąż udowadnia, że na dzisiaj jest najbardziej uniwersalnym modelem oferującym najbardziej kreatywne możliwości współpracy. Ogarnia matematykę, bzdurne zliczanie literek, ale też wciela się w role i kreatywnie tłumaczy skomplikowane pojęcia. Szef.
Bard potrafi odpłynąć i źle literować, ale jego “wyszukiwarkowy background” wskazuje, że z faktami i źródłami radzi sobie całkiem dobrze. To duży plus, bo większość użytkowników nadal myśli o LLMach jak o lepszych wyszukiwarkach. Niestety, w Polsce Bard nie pracuje jeszcze w oparciu o Gemini Pro, więc test powtórzę za kolejne kilka miesięcy.
Claude w Polsce… w ogóle nie jest dostępny. Testy realizowałem przy pomocy VPNa. Zobaczyłem naprawdę ciekawy model tekstowy, który udziela zwięzłych odpowiedzi, a nawet w darmowej wersji opiera się o najlepszy z dostępnych modeli czyli Claude 2.1 (patrzę na was, @OpenAI ). Niestety, rozpoznawania obrazów w nim nie znajdziemy, więc ostatniego zadania po prostu nie był w stanie realizować. Podobnie jak z Gemini Pro, czekam na dostępność w Polsce. Ah ta 🇪🇺.
Jeśli chcecie dowiedzieć się więcej na temat bezpiecznego i świadomego korzystania z LLMów, zachęcam do zapisania się na newsletter i oczekiwania na nowy ebook - już niebawem opublikujemy dla was materiał podsumowujący kluczowe informacje ze świata AI, AD 2024.