· Tutorial
Jak uzyskać dostęp do GPT-4 przez API OpenAI?

TL;DR
Dostęp do OpenAI API jest w 2024r. w pełni otwarty. Całą integrację opisujemy w poniższym artkule.
UPDATE: Artykuł zaktualizowany w lipcu 2024r.
Nowe możliwości
Publicznie dostępne modele generatywnej sztucznej inteligencji sprawiają, że wzbogacanie projektów o nowe funkcje oparte o tekst, obrazy czy audio stało się zaskakująco łatwe. To, co kiedyś wymagało zespołu naukowców i budowanych w zaciszu biura modeli sztucznej inteligencji, teraz jest realizowane w zdecydowanie bardziej dostępny sposób.
W tym artykule dowiesz się, jak przy pomocy modeli takich jak GPT-3.5, GPT-4 a także GPT-4o realizować analizę fragmentu tekstu, ekstrakcję najważniejszych pojęć, podsumowywanie dokumentów i wyszukiwanie podobieństw pomiędzy zbiorami danych. To wszystko za niewielką opłatą, która jest w zasięgu każdego, kto chce zacząć korzystać z tych narzędzi.
Dostęp do OpenAI API
Jeszcze kilka miesięcy temu dostęp do platformy OpenAI wymagał zapisu na listę oczekujących. W 2024r. to ograniczenie zostało zniesione, a przygotowanie do integracji sprowadza się do założenia konta na stronie platform.openai.com. Zacznijmy od tego kroku, a następnie przejdźmy do konfiguracji API i pierwszych zapytań do modelu:
Konto założysz klikając na przycisk “Sign up” widoczny w górnej części interfejsu. Sam proces wymaga podania adresu email, a także podstawowych danych takich jak imię i nazwisko. Na tym etapie nie trzeba jeszcze konfigurować płatności, co dla niezdecydowanych może być dodatkowym atutem.
Po potwierdzeniu adresu email możemy przejść do przeglądu API i pierwszych zapytań do modelu.
Środowisko testowe
Po założeniu konta, a jeszcze przed skonfigurowaniem płatności, mamy już dostęp do pełnej dokumentacji oraz tzw. Playgroundu w trybie read-only, czyli środowiska testowego.
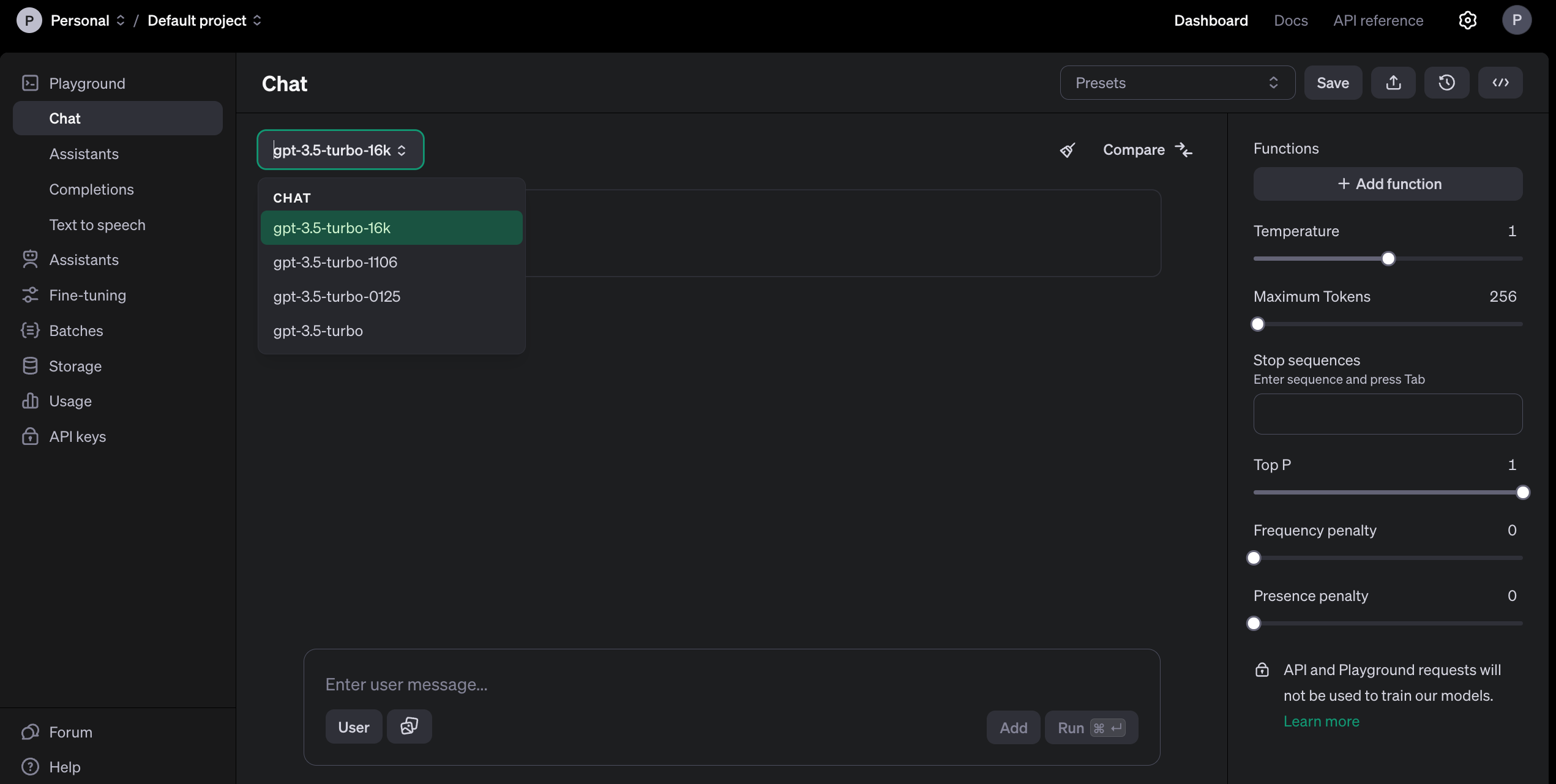
W tym miejscu możesz zobaczyć, jakie parametry będą akceptować wystawione modele. Dostępne elementy interfejsu użytkownika, takie jak pola do sterowania tzw. temperaturą, mechanizmem generowania tokenów czy definiowaniem funkcji, bezpośrednio przekładają się na integracje z poziomu kodu. Widać to zresztą po kliknięciu przycisku “View code” znajdującego się poniżej avatara użytkownika:
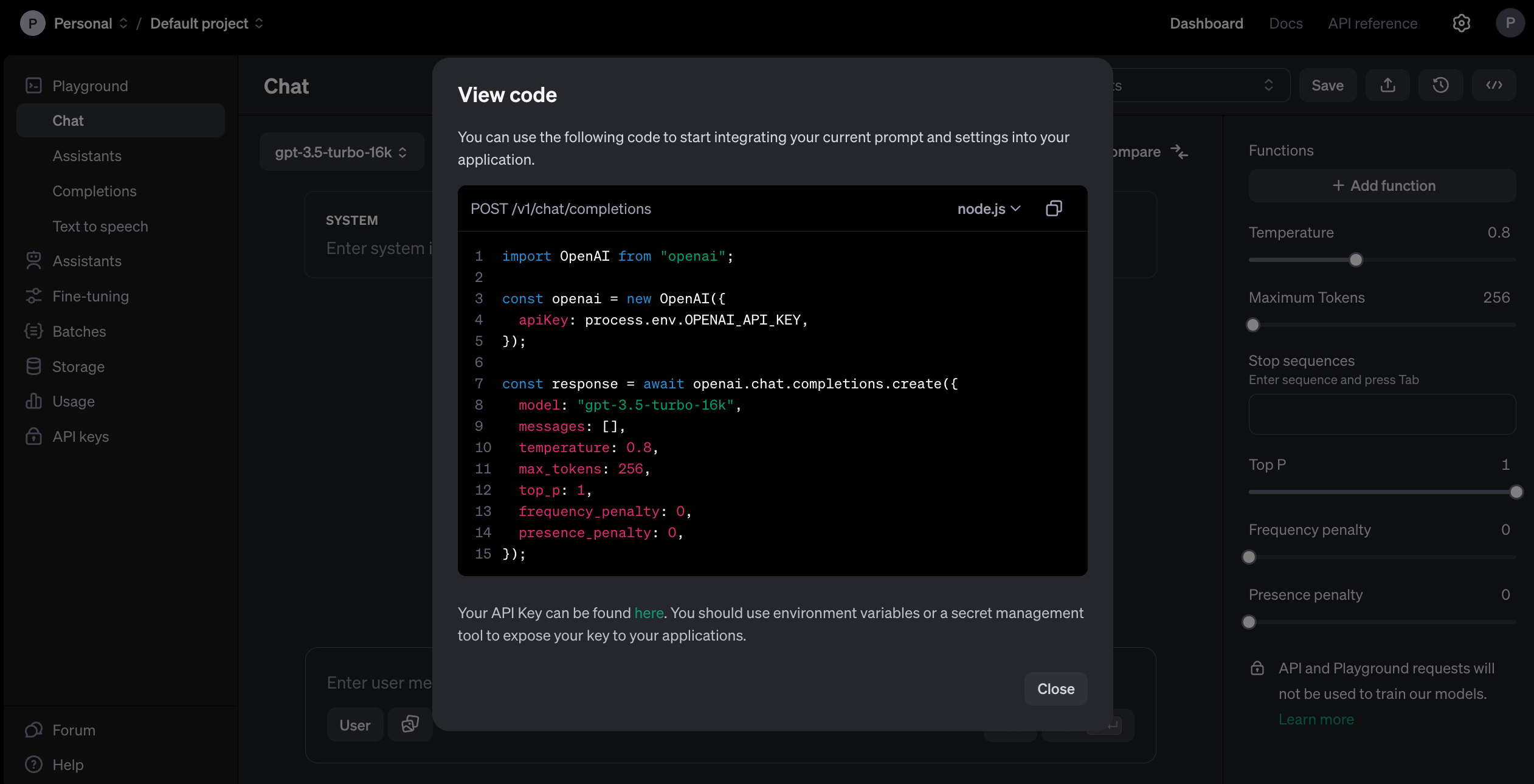
Aby skorzystać z tego środowiska, a także realizować docelowe integracje, musimy jednak przejść do konfiguracji płatności i zdefiniowania limitów korzystania z API.
Konfiguracja płatności
Do momentu skonfigurowania płatności, nasze konto ma status testowy. Możemy podglądać Playground i dokumentację, ale same modele są niedostępne.
Aby to zmienić, wejdźmy na stronę płatności i dodajmy szczegóły karty, z której planujemy korzystać:
Po dodaniu karty, musimy jeszcze doładować nasze konto. Platforma OpenAI działa teraz w trybie “pay-as-you-go”, co oznacza, że płacimy tylko za wykorzystane zasoby. Minimalna wartość doładowania to 5$ - od takiej kwoty możemy rozpocząć korzystanie z samego API.
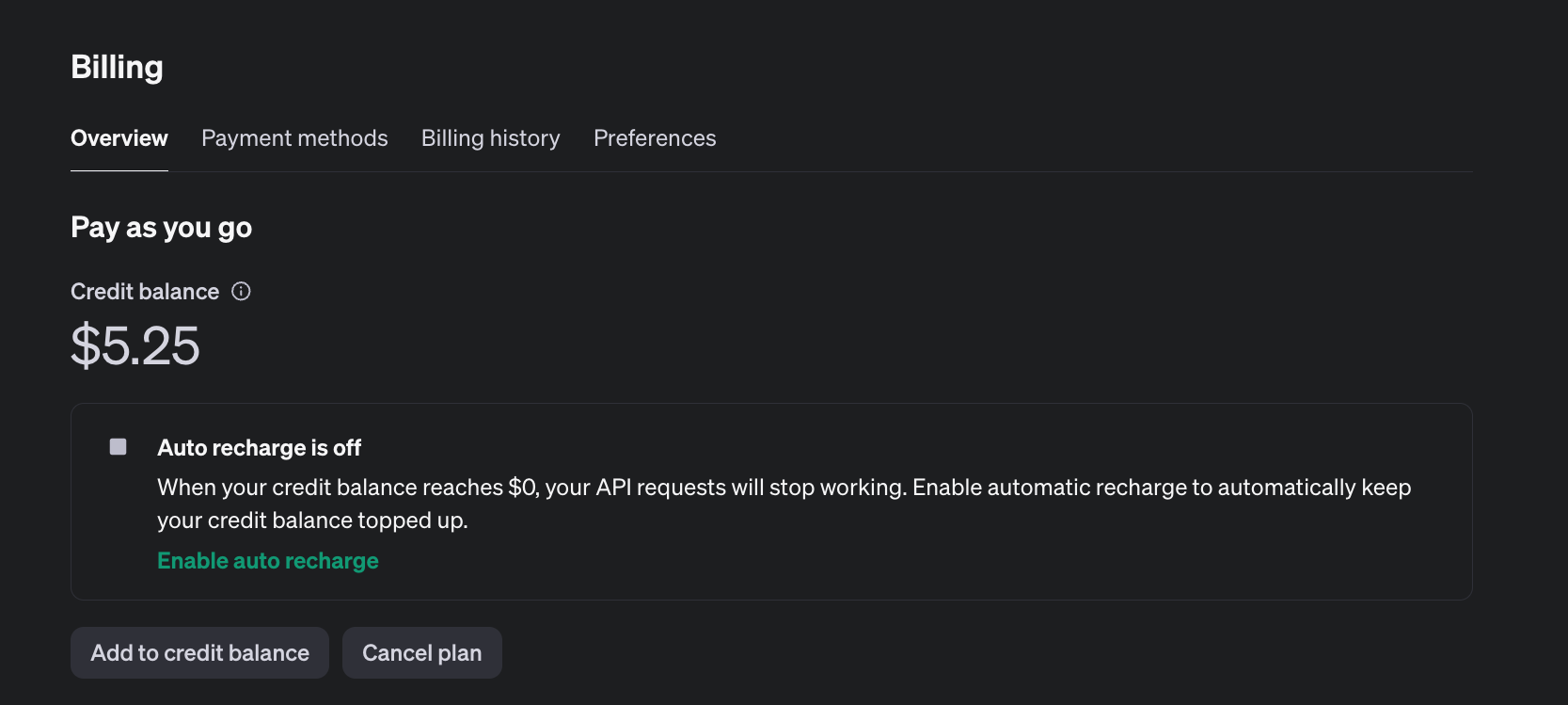
Od teraz możemy już korzystać z wszystkich modeli, a także testować komunikację poprzez Playground:
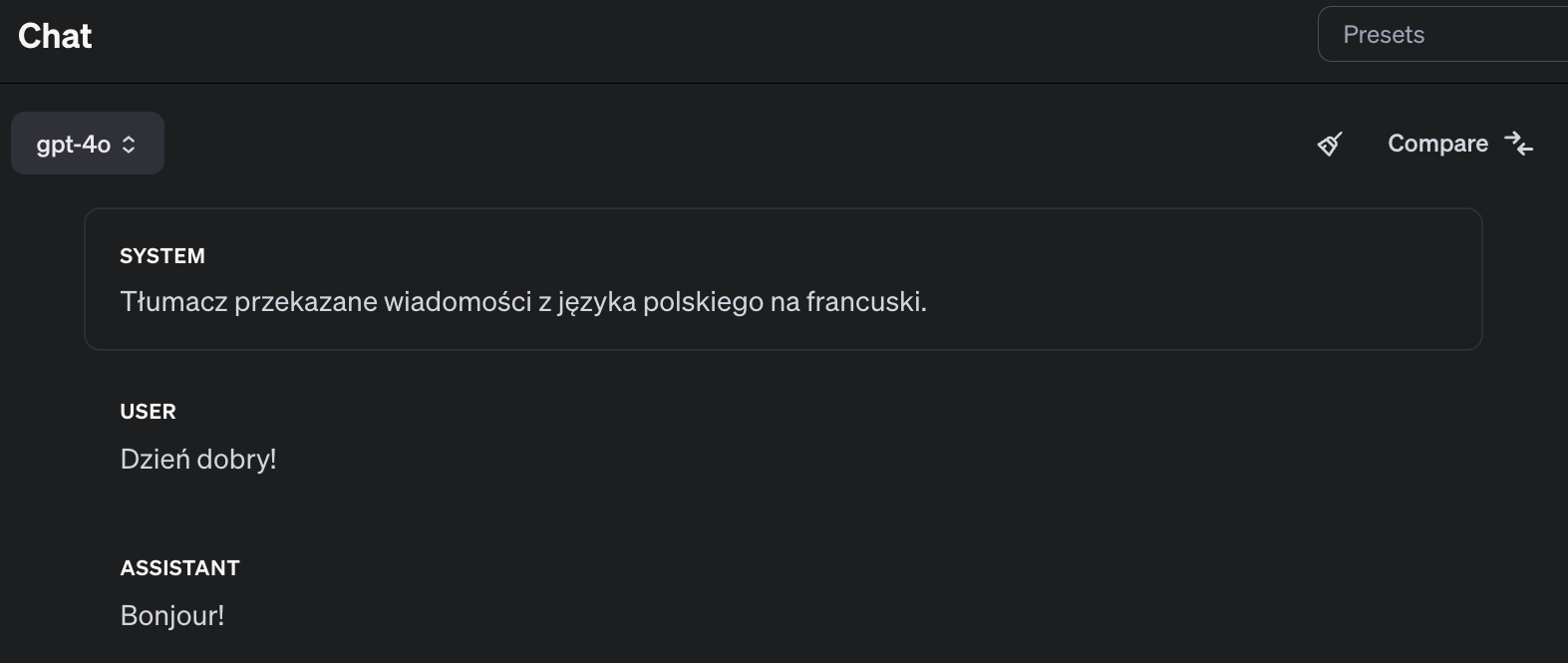
Integracje z modelami OpenAI
Pierwszą rzeczą, jaką musimy wykonać do zbudowania technicznej integracji, jest wygenerowanie klucza dostępowego. Można go w łatwy sposób utworzyć z poziomu ustawień konta:
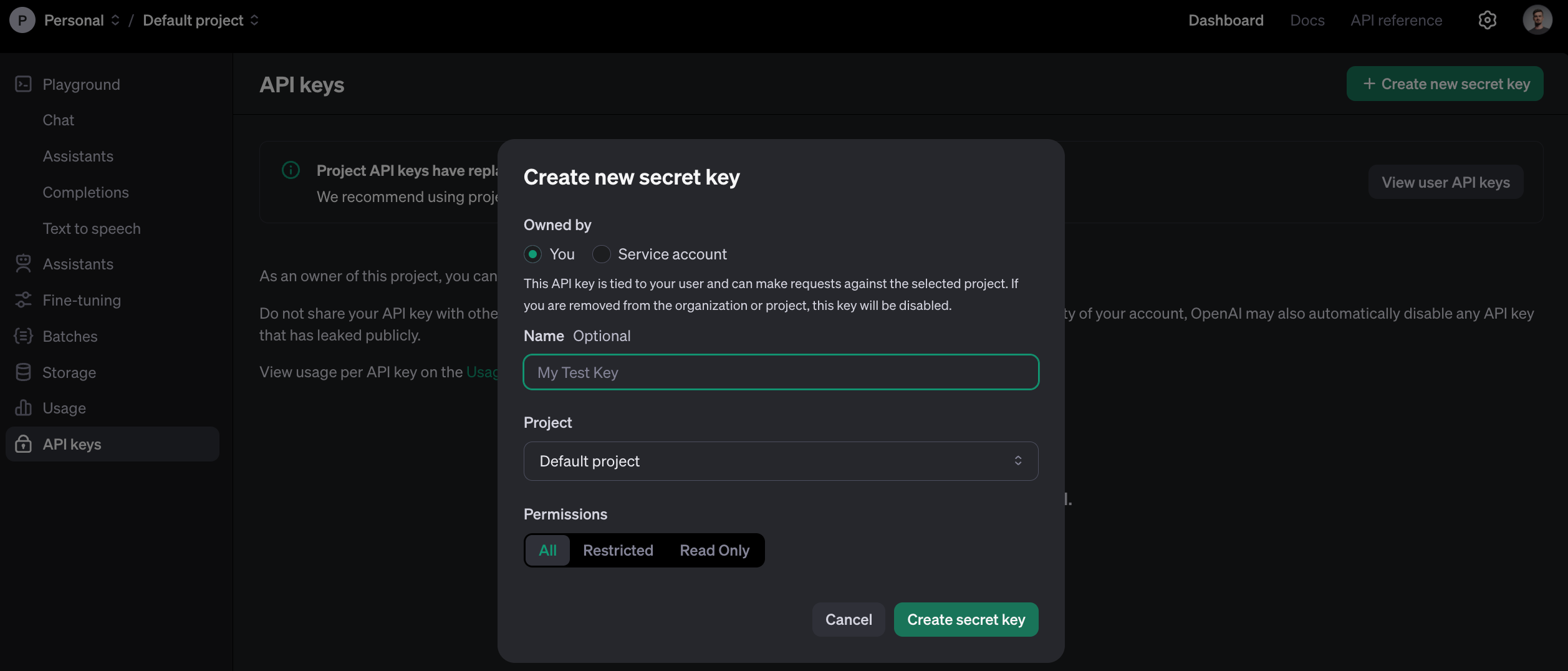
Mając wygenerowany klucz i będąc na koncie płatnym nie pozostaje nam nic innego, jak przejść do dokumentacji samego modelu aby zapoznać się z właściwą integracją. Modele językowe, takie jak GPT-3.5, GPT-4 a także GPT-4o są częścią tzw. Chat API - właśnie tam znajdziesz szczegóły i parametry, które musisz przekazać w zapytaniu do modelu.
Przykładowe zapytanie w projekcie opartym o JavaScript i Node.js może wyglądać następująco:
import OpenAI from 'openai';
const openai = new OpenAI({
apiKey: process.env['OPENAI_API_KEY'],
});
async function main() {
const completion = await openai.chat.completions.create({
messages: [
{ role: 'system', content: 'Tłumaczysz wiadomości z języka polskiego na język francuski.' },
{ role: 'user', content: 'Dzień dobry!' },
],
model: 'gpt-4o',
});
console.log(completion.choices[0]);
}
main();Paczka z której korzystamy to openai. Do autentykacji z API wykorzystuje ona zmienną środowiskową OPENAI_API_KEY z wcześniej wygenerowanym kluczem. Możemy ją podawać w sposób jawny, tak jak powyżej, albo skorzystać z konwencji i pominąć (rekomendujemy jawne podawanie zmiennych).
Przy pomocy tzw. Completions API realizujemy komunikację z modelem. Sam model generuje wiadomości na podstawie tablicy messages starając się kontynuować przekazany tekst w najlepszy możliwy sposób. Aby odróżnić wiadomości techniczne od tych, które podaje użytkownik, korzystamy z trzech ról:
- System - wiadomości techniczne, działające jako zbiór reguł i oczekiwań względem całej konwersacji
- User - wiadomości pochodzące od użytkownika
- Assistant - wiadomości wygenerowane przez model
Dodatkowe parametry, które możesz przekazać do zapytania, zostały opisane w tym miejscu.
Na początku możesz testować nawet najprostsze komunikaty - podany fragment kodu w zupełności wystarczy do stworzenia pierwszych eksperymentów opartych o LLMy. Na tym etapie nie pozostaje ci nic innego, jak tylko uruchomić wyobraźnię i zaprojektować takie rozwiązania oparte o modele językowe, które pokażą ci prawdziwy potencjał sztucznej inteligencji.
Ile to kosztuje?
Biorąc pod uwagę zaawansowane możliwości samego modelu, cennik zdefiniowany przez OpenAI nie jest szczególnie kontrowersyjny. Podstawą rozliczenia jest liczba tzw. tokenów wykorzystywanych w komunikacji z modelem, a na całościowy koszt wpływa zarówno rozmiar wiadomości od użytkownika, jak i rozmiar generowanych odpowiedzi.
Czym jest token? Token to podstawowa jednostka informacji (słów, znaków) którą wykorzystują modele językowe do generowania i przewidywania tekstu. Zgodnie z dokumentacją OpenAI można założyć, że tysiąc tokenów to ok. 750 słów. Wg Wikipedii, przeciętna książka w języku angielskim zawiera ok. 250-300 słów na stronę, a więc mniej niż pięćset tokenów.
Dlaczego to ważne? Dlatego, że ceny zdefiniowane są właśnie w relacji do wykorzystywanych tokenów. Na dzisiaj rozliczenie za najlepszy model (GPT-4o) wygląda następująco:

Do liczenia tokenów możesz wykorzystać narzędzia takie jak:
- tiktoken od firmy OpenAI
- Semantic Kernel od Microsoftu
Mając takie dane, możesz teraz w łatwy sposób zdefiniować swój budżet korzystania z modeli językowych (np. 50zł / miesiąc) i sprawdzić, ile tekstu możesz faktycznie przeprocesować z narzędziem, które dzisiaj opisuję.
Pamiętaj również, że nie jesteś ograniczony do jednego modelu. Możesz korzystać z kilku jednocześnie (np. GPT-3.5 w prostych zadaniach, a GPT-4o w złożonych), a także testować różne konfiguracje i parametry zapytań. Wszystko to pozwala na zbudowanie złożonych integracji, które wzbogacą twoje projekty o nowe funkcje i możliwości przy zachowaniu optymalnego kosztu integracji.
Co dalej?
Możliwości, jakie dają nam współczesne modele językowe, są naprawdę zdumiewające.
Za stosunkowo niewielką opłatą możemy realizować złożone integracje i analizę rozmaitych formatów danych, a głównym ograniczeniem jest na dzisiaj programista i jego wyobraźnia. Co więcej, korzystając z API firmy OpenAI uzyskujemy dostęp nie tylko do GPT-3.5/4, ale również do modeli przetwarzających obrazy (DALL-E) lub dźwięk (Whisper), co podnosi możliwości całej integracji o kolejne kilka poziomów.
Zobacz artykuł, w którym opisujemy wykorzystanie AI w kontekście transkrypcji naszych podcastów - znajdziesz go w tym miejscu.